Though I have worked on pattern recognition in the past I have always wanted to work with Neural Networks for the same. However for some reason or the other I could never do so, I could not even take it as an elective subject due to some constraints. Over the last two years or so I have been promising myself and ordering myself to stick to a schedule and study ANNs properly, however due to a combination of procrastination, over-work and bad planning I have never been able to do anything with them.
However I have now got the opportunity to work with Support Vector Machines and over the past some time I have been reading extensively on the same and have been trying to get playing with them. Now that the actual implementation and work is set to start I am pretty excited to work with them. It is nice that I get to work with SVMs though I could not with ANNs.
Support Vector Machine is a classifier derived from statistical learning theory by Vladimir Vapnik and his co-workers. The foundations for the same were laid by him as late as the 1970s SVM shot to prominence when using pixel maps as input it gave an accuracy comparable with sophisticated Neural Networks with elaborate features in a handwriting recognition task.
Traditionally Neural Networks based approaches have suffered some serious drawbacks, especially with generalization, producing models that can overfit the data. SVMs embodies the structural risk minimization principle that is shown superior to the empirical risk minimization that neural networks use. This difference gives SVMs the greater ability to generalize.
However learning how to work with SVMs can be challenging and somewhat intimidating at first. When i started reading on the topic I took the books by Vapnik on the subject but could not make much head or tail. I could only attain a certain degree of understanding, nothing more. To specialize in something I do well when I start off as a generalist, having a good and quite correct idea of what is exactly going on. Knowing in general what is to be done and what is what, after this initial know-how makes me comfortable I reach the stage of starting with the mathematics which gives profound understanding as anything without mathematics is meaningless. However most books that I came across missed the first point for me, and it was very difficult to make a headstart. There was a book which I could read in two days that helped me get that general picture quite well. I would highly recommend it for most who are in the process of starting with SVMs.The book is titled Support Vector Machines and other Kernel Based Learning methods and is authored by Nello Cristianini and John-Shawe Taylor.

I would highly recommend people who are starting with Support Vector Machines to buy this book. It can be obtained easily over Amazon.
This book has very less of a Mathematical treatment but it makes clear the ideas involved and this introduces a person studying from it to think more clearly before he/she can refine his/her understanding by reading something heavier mathematically. Another that I would highly recommend is the book Support Vector Machines for Pattern Classification by Shigeo Abe.
Another book that I highly recommend is Learning with Kernels by Bernhard Scholkopf and Alexander Smola. Perfect book for beginners.

Only after one has covered the required stuff from here that I would suggest Vapnik’s books which then would work wonderfully well.
Other than the books there are a number of Video Lectures and tutorials on the Internet that can work as well!
Below is a listing of a large number of good tutorials on the topic. I don’t intend to flood a person interested in starting with too much information, where ever possible i have described what the document carries so that one could decide what should suffice for him/her on the basis of need. Also I have star-marked some of the posts. This marks the ones that i have seen and studied from personally and found them most helpful and i am sure they would work the same way with both beginners and people with reasonable experience alike.
—
Webcasts/ Video Lectures on Learning Theory, Support Vector Machines and related ideas:
EDIT: For those interested. I had posted about a course on Machine Learning that has been provided by Stanford university. It too is suited for an introduction to Support Vector Machines. Please find the post here. Also this comment might be helpful, suggestions to it according to your learning journey are also welcome.
1. *Machine Learning Workshop, University of California at Berkeley. This series covers most of the basics required. Beginners can skip the sessions on Bayesian models and Manifold Learning.
Workshop Outline:
Session 1: Classification.
Session 2: Regression.
Session 3: Feature Selection
Session 4: Diagnostics
Session 5: Clustering
Session 6: Graphical Models
Session 7: Linear Dimensionality Reduction
Session 8: Manifold Learning and Visualization
Session 9: Structured Classification
Session 10: Reinforcement Learning
Session 11: Non-Parametric Bayesian Models
2. Washington University. Beginners might be interested on the sole talk on the topic of Supervised Learning for Computer Vision Applications or maybe in the talk on Dimensionality Reduction.
3. Reinforcement Learning, Universitat Freiburg.
4. Deep Learning Workshop. Good talks, But I’d say these are meant for only the highly interested.
5. *Introduction to Learning Theory, Olivier Bousquet.
This tutorial focuses on the “larger picture” than on mathematical proofs, it is not restricted to statistical learning theory however. The course comprises of five lectures and is quite good to watch. The Frenchman is both smart and fun!
6. *Statistical Learning Theory, Olivier Bousquet. This course gives a detailed introduction to Learning Theory with a focus on the Classification problem.
Course Outline:
Probabilistic and Concentration inequalities, Union Bounds, Chaining, Measuring the size of a function class, Vapnik Chervonenkis Dimension, Shattering Dimensions and Rademacher averages, Classification with real valued functions.
7. *Statistical Learning Theory, Olivier Bousquet. This is not the repeat of the above course. This one is a more recent lecture series than the above actually. This course has six lectures. Another excellent set.
Course Outline:
Learning Theory: Foundations and Goals
Learning Bounds: Ingredients and Results
Implications: What to conclude from bounds
7. Advanced Statistical Learning Theory, Olivier Bousquet. This set of lectures compliment the above courses on statistical learning theory and give a more detailed exposition of the current advancements in the same.This course has three lectures.
Course Outline:
PAC Bayesian bounds: a simple derivation, comparison with Rademacher averages, Local Rademacher complexity with classification loss, Talagrand’s inequality. Tsybakov noise conditions, Properties of loss functions for classification (influence on approximation and estimation, relationship with noise conditions), Applications to SVM – Estimation and approximation properties, role of eigenvalues of the Gram matrix.
8. *Statistical Learning Theory, John-Shawe Taylor, University of London. One plus point of this course is that is has some good English. Don’t miss this lecture as it has been given by the same professor whose book we just discussed.
9. *Learning with Kernels, Bernhard Scholkopf.
This course covers the basics for Support Vector Machines and related Kernel methods. This course has six lectures.
Course Outline:
Kernel and Feature Spaces, Large Margin Classification, Basic Ideas of Learning Theory, Support Vector Machines, Other Kernel Algorithms.
10. Kernel Methods, Alexander Smola, Australian National University. This is an advanced course as compared to the above and covers exponential families, density estimation, and conditional estimators such as Gaussian Process classification, regression, and conditional random fields, Moment matching techniques in Hilbert space that can be used to design two-sample tests and independence tests in statistics.
11. *Introduction to Kernel Methods, Bernhard Scholkopf, There are four parts to this course.
Course Outline:
Kernels and Feature Space, Large Margin Classification, Basic Ideas of Learning Theory, Support Vector Machines, Examples of Other Kernel Algorithms.
12. Introduction to Kernel Methods, Partha Niyogi.
13. Introduction to Kernel Methods, Mikhail Belkin, Ohio State University.This lecture is second in part to the above.
14. *Kernel Methods in Statistical Learning, John-Shawe Taylor.
15. *Support Vector Machines, Chih-Jen Lin, National Taiwan University. Easily one of the best talks on SVM. Almost like a run-down tutorial.
Course Outline:
Basic concepts for Support Vector Machines, training and optimization procedures of SVM, Classification and SVM regression.
16. *Kernel Methods and Support Vector Machines, Alexander Smola. A comprehensive six lecture course.
Course Outline:
Introduction of the main ideas of statistical learning theory, Support Vector Machines, Kernel Feature Spaces, An overview of the applications of Kernel Methods.
—
Additional Courses:
1. Basics of Probability and Statistics for Machine Learning, Mikaela Keller.
This course covers most of the basics that would be required for the above courses. However sometimes the shooting quality is a little shady. This talk seems to be the most popular on the video lectures site, one major reason in my opinion is that the lady delivering the lecture is quite pretty!
2. Some Mathematical Tools for Machine Learning, Chris Burges.
3. Machine Learning Laboratory, S.V.N Vishwanathan.
4. Machine Learning Laboratory, Chrisfried Webers.
—
Introductory Tutorials (PDF/PS):
1. *Support Vector Machines with Applications (Statistical Science). Click here >>
2. *Support Vector Machines (Marti Hearst, UC Berkeley). Click Here >>
3. *Support Vector Machines- Hype or Hallelujah (K. P. Bennett, RPI). Click Here >>
4. Support Vector Machines and Pattern Recognition (Georgia Tech). Click Here >>
5. An Introduction to Support Vector Machines in Data Mining (Georgia Tech). Click Here >>
6. University of Wisconsin at Madison CS 769 (Zhu). Click Here >>
7. Generalized Support Vector Machines (Mangasarian, University of Wisconsin at Madison). Click Here >>
8. *A Practical Guide to Support Vector Classification (Hsu, Chang, Lin, Via U-Michigan Ann Arbor). Click Here >>
9. *A Tutorial on Support Vector Machines for Pattern Recognition (Christopher J.C Burges, Bell Labs Lucent Technologies, Data mining and knowledge Discovery). Click Here >>
10. Support Vector Clustering (Hur, Horn, Siegelmann, Journal of Machine Learning Research. Via MIT). Click Here >>
11. *What is a Support Vector Machine (Noble, MIT). Click Here >>
12. Notes on PCA, Regularization, Sparisty and Support Vector Machines (Poggio, Girosi, MIT Dept of Brain and Cognitive Sciences). Click Here >>
13. *CS 229 Lecture Notes on Support Vector Machines (Andrew Ng, Stanford University). Click Here >>
—
Introductory Slides (mostly lecture slides):
1. Support Vector Machines in Machine Learning (Arizona State University). Click here >>
Lecture Outline:
What is Machine Learning, Solving the Quadratic Programs, Three very different approaches, Comparison on medium and large sets.
2. Support Vector Machines (Arizona State University). Click Here >>
Lecture Outline:
The Learning Problem, What do we know about test data, The capacity of a classifier, Shattering, The Hyperplane Classifier, The Kernel Trick, Quadratic Programming.
3. Support Vector Machines, Linear Case (Jieping Ye, Arizona State University). Click Here >>
Lecture Outline:
Linear Classifiers, Maximum Margin Classifier, SVM for Separable data, SVM for non-separable data.
4. Support Vector Machines, Non Linear Case (Jieping Ye, Arizona State University). Click Here >>
Lecture Outline:
Non Linear SVM using basis functions, Non-Linear SVMs using Kernels, SVMs for Multi-class Classification, SVM path, SVM for unbalanced data.
5. Support Vector Machines (Sue Ann Hong, Carnegie Mellon). Click Here >>
6. Support Vector Machines (Carnegie Mellon University Machine Learning 10701/15781). Click Here >>
7. Support Vector Machines and Kernel Methods (CMU). Click Here >>
8. SVM Tutorail (Columbia University). Click Here >>
9. Support Vector Machines (Via U-Maryland at College Park). Click Here >>
10. Support Vector Machines: Algorithms and Applications (MIT OCW). Click Here >>
11. Support Vector Machines (MIT OCW). Click Here >>
—
Papers/Notes on some basic related ideas (No estoric research papers here):
1. Robust Feature Induction for Support Vector Machines (Arizona State University). Click Here >>
2. Hidden Markov Support Vector Machines (Brown University). Click Here >>
3. *Training Data Set for Support Vector Machines (Brown University). Click Here >>
4. Support Vector Machines are Universally Consistent (Journal Of Complexity). Click Here >>
5. Feature Selection for Classification of Variable Length Multi-Attribute Motions (Li, Khan, Prabhakaran). Click Here >>
6. Selecting Data for Fast Support Vector Machine Training (Wang, Neskovic, Cooper). Click Here >>
7. *Normalization in Support Vector Machines (Caltech). Click Here >>
8. The Support Vector Decomposition Machine (Periera, Gordon, Carnegie Mellon). Click Here >>
9. Semi-Supervised Support Vector Machines (Bennett, Demiriz, RPI). Click Here >>
10. Supervised Clustering with Support Vector Machines (Finley, Joachims, Cornell University). Click Here >>
11. Metric Learning: A Support Vector Approach (Cornell University). Click Here >>
12. Training Linear SVMs in Linear Time (Joachims, Cornell Unversity). Click Here >>
13. *Rule Extraction from Linear Support Vector Machines (Fung, Sandilya, Rao, Siemens Medical Solutions). Click Here >>
14. Support Vector Machines, Reproducing Kernel Hilbert Spaces and Randomizeed GACV (Wahba, University of Wisconsian at Madison). Click Here >>
15. The Mathematics of Learning: Dealing with Data (Poggio, Girosi, AI Lab, MIT). Click Here >>
16. Training Invariant Support Vector Machines (Decoste, Scholkopf, Machine Learning). Click Here >>
—
*As I have already mentioned above, the star marked courses/lectures/tutorials/papers are the ones that I have seen and studied from personally (and hence can vouch for) and these in my opinion should work best for beginners.
Onionesque Reality Home >>
Read Full Post »



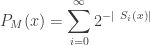
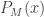

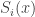
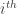
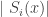


















 .
. and orientation
and orientation  . Since the response at any given time is dependent solely on the present and not the previous history, it would be sufficient to specify the transition probability from one location
. Since the response at any given time is dependent solely on the present and not the previous history, it would be sufficient to specify the transition probability from one location  to another place and orientation
to another place and orientation  an instant later. Thus the movement of each individual agent can be considered roughly to be a continuous
an instant later. Thus the movement of each individual agent can be considered roughly to be a continuous  .
.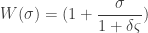
 .
. may be considered. This parameter measures the degree of randomness by which an agent can follow a pheromone trail. For low values of
may be considered. This parameter measures the degree of randomness by which an agent can follow a pheromone trail. For low values of  . This signifies the sensory capability. It describes the fact that the ants ability to sense pheromone decreases somewhat at higher concentrations. Something like a saturation scenario.
. This signifies the sensory capability. It describes the fact that the ants ability to sense pheromone decreases somewhat at higher concentrations. Something like a saturation scenario. . Thus using all these parameters we can define a single parameter, the average pheromonal field
. Thus using all these parameters we can define a single parameter, the average pheromonal field  . Where
. Where  is what i mentioned above, the rate of scent decay.
is what i mentioned above, the rate of scent decay.
 .
. is zero. Each ant deposits pheromone at a decided rate
is zero. Each ant deposits pheromone at a decided rate  .
.













