For the past couple of years, I have had a couple of questions about machine learning research that I have wanted to ask some experts, but never got the chance to do so. I did not even know if my questions made sense at all. I would probably write about them on a blog post soon enough.
It is however ironical that I came to know my questions were valid and well discussed (I never knew what to search for them, I used expressions not used by researchers) only by the death of Ray Solomonoff (he was one researcher who worked on it, and an obituary on him highlighted his work on it, something I missed). Solomonoff was one of the founding fathers of Artificial Intelligence as a field and Machine Learning as a discipline within it. It must be noted that he was one of the few attendees at the 1956 Dartmouth Conference, basically an extended brain storming session that started AI formally as a field. The other attendees were : Marvin Minsky, John McCarthy, Allen Newell, Herbert Simon, Arthur Samuel, Oliver Selfridge, Claude Shannon, Nathaniel Rochester and Trenchand Moore. His 1950-52 papers on networks are regarded as the first statistical analysis of the same. Solomonoff was thus a towering figure in AI and Machine Learning.

[Ray Solomonoff : (25 July 1926- 7 December 2009)]
Solomonoff is widely considered as the father of Machine Learning for circulating the first report on the same in 1956. His particular focus was on the use of probability and its relation to learning. He founded the idea of Algorithmic Probability (ALP) in a 1960 paper at Caltech, an idea that gives rise to Kolmogorov Complexity as a side product. A. N. Kolmogorov independently discovered similar results and came to know of and acknowledged Solomonoff’s earlier work on Algorithmic Information Theory. His work however was relatively unknown in the west than in the soviet union, which is why Algorithmic Information Theory is mostly referred to as Kolmogorov complexity rather than “Solomonoff Complexity”. Kolmogorov and Solomonoff approached the same framework from different directions. While Kolmogorov was concerned with randomness and Information Theory, Solomonoff was concerned with inductive reasoning. And in doing so he discovered ALP and Kolomogorov Complexity years before anyone did. I would write below on only one aspect of his work that I have studied to some degree in the past year.

Solomonoff With G.J Chaitin, another pioneer in Algorithmic Information Theory
[Image Source]
The Universal Distribution:
His 1956 paper, “An inductive inference machine” was one of the seminal papers that used probability in Machine Learning. He outlined two main problems which he thought (correctly) were linked.
The Problem of Learning in Humans : How do you use all the information that you gather in life in making decisions?
The Problem of Probability : Given you have some data and some a-priori information, how can you make the best possible predictions for the future?
The problem of learning is more general and related to the problem of probability. Solomonoff noted that the Machine learning was simply the process of approximating ideal probabilistic predictions for practical use.
Building on his 1956 paper, he discovered probabilistic languages for induction at a time when it was considered out of fashion. And discovered the Universal Distribution.
All induction problems could be basically reduced to this form : Given a sequence of binary symbols how do you extrapolate it? The answer being that we could assign a probability to a sequence and then use Bayes Theorem to make a prediction on which particular continuation of a string was how likely. That gives rise to an even more difficult question that was the basic question for a lot of Solomonoff’s work and on Algorithmic Probability/Algorithmic Information Theory. This question is : How do you assign probabilities to strings?
Solomonoff approached this problem using the idea of a Universal Turing Machine. Suppose this Turing Machine has three types of tapes, an unidirectional input tape, an unidirectional output tape and a bidirectional working tape. Suppose this machine will take some binary string as input and it may give a binary string as output.
It could do any of the following :
1. Print out a string after a while and then come to a stop.
2. It could print an infinite output string.
3. It could go in an infinite loop for computing the string and not output anything at all (Halting Problem).
For a string  , the ALP would be as follows :
, the ALP would be as follows :
If we feed some bits at random to our Turing Machine, there will always be some probability that the output would start with a string . This probability is the algorithmic or universal probability of the string .
The ALP would be given as :
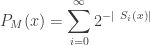
Where 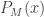 would be the universal probability of string with respect to the universal turing machine
would be the universal probability of string with respect to the universal turing machine  . To understand the placement of
. To understand the placement of 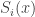 in the above expression, let’s discuss it a little.
in the above expression, let’s discuss it a little.
There could be many random strings that after being processed by the Turing Machine give an output string that begins with string . And is the 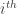 such string. Each such string carries a description of . And since we want to consider all cases, we take the summation. In the expression above
such string. Each such string carries a description of . And since we want to consider all cases, we take the summation. In the expression above 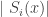 gives the length of a string and
gives the length of a string and  the probability that the random input
the probability that the random input  would output a string starting with .
would output a string starting with .
This definition of ALP has the following properties that have been stated and proved by Solomonoff in the 60s and the 70s.
1. It assigns higher probabilities to strings with shorter descriptions. This is the reverse of something like Huffman Coding.
2. The value for ALP would be independent of the type of the universal machine used.
3. ALP is incomputible. This is the case because of the halting problem. Infact it is this reason that it has not received much attention. Why get interested in a model that is incomputible? However Solomonoff insisted that approximations to the ALP would be much better than existing systems and that getting the exact ALP is not even needed.
4. is a complete description for . That means any pattern in the data could be found by using  . This means that the universal distribution is the only inductive principle that is complete. And approximations to it would be much desirable.
. This means that the universal distribution is the only inductive principle that is complete. And approximations to it would be much desirable.
__________
Solomonoff also worked on Grammar discovery and was very interested in Koza’s Genetic Programming system, which he believed could lead to efficient and much better machine learning methods. He published papers till the ripe old age of 83 and is definitely inspiring for the love of his work. Paul Vitanyi notes that :
It is unusual to find a productive major scientist that is not regularly employed at all. But from all the elder people (not only scientists) I know, Ray Solomonoff was the happiest, the most inquisitive, and the most satisfied. He continued publishing papers right up to his death at 83.
Solomonoff’s ideas are still not exploited to their full potential and in my opinion would be necessary to explore to build the Machine Learning dream of never-ending learners and incremental + synergistic Machine Learning. I would write about this in a later post pretty soon. It was a life of great distinction and a life well lived. I also wish strength and peace to his wife Grace and his nephew Alex.

The five surviving (in 2006) founders of AI who met in 2006 to commemorate 50 years of the Dartmouth Conference. From left : Trenchand Moore, John McCarthy, Marvin Minsky, Oliver Selfridge and Ray Solomonoff
__________
Refernces and Links:
1. Ray Solomonoff’s publications.
2. Obituary: Ray Solomonoff – The founding father of Algorithmic Information Theory by Paul Vitanyi
3. The Universal Distribution and Machine Learning (PDF).
4. Universal Artificial Intelligence by Marcus Hutter (videolectures.net)
5. Minimum Description Length by Peter Grünwald (videolecures.net)
6. Universal Learning Algorithms and Optimal Search (Neural Information Processing Systems 2002 workshop)
__________
Onionesque Reality Home >>
Read Full Post »








