Recently I was going through Shannon’s original 1948 Information Theory paper and a paper by Kolmogorov from 1983 that places the differences between “Shannon Information” and “Algorithmic Information” in sharp relief. After much information diffusion over the past decades the difference is quite obvious and particularly interesting to contrast nonetheless. Nevertheless I found these two paragraphs from these two papers interesting, if for nothing then for historical reasons.
“The fundamental problem of communication is that of reproducing at one point either exactly or approximately a message selected at another point. Frequently the messages have meaning; that is they refer to or are correlated according to some system with certain physical or conceptual entities. These semantic aspects of communication are irrelevant to the engineering problem. The significant aspect is that the actual message is one selected from a set of possible messages. The system must be designed to operate for each possible selection, not just the one which will actually be chosen since this is unknown at the time of design.” (C. E. Shannon, A Mathematical Theory of Communication, 1948).
“Our definition of the quantity of information has the advantage that it refers to individual objects and not to objects treated as members of a set of objects with a probability distribution given on it. The probabilistic definition can be convincingly applied to the information contained, for example, in a stream of congratulatory telegrams. But it would not be clear how to apply it, for example, to an estimate of the quantity of information contained in a novel or in the translation of a novel into another language relative to the original. I think that the new definition is capable of introducing in similar applications of the theory at least clarity of principle.” (A. N. Kolmogorov, Combinatorial Foundations of Information Theory and the Calculus of Probabilities, 1983).
Note the reference that Shannon makes is to a message selected from a set of possible messages (and hence the use of probability theory), his problem was mainly concerned with the engineering application of communication. While Kolmogorov talks of individual objects and is not directly concerned with communication and hence the usage of computability (the two notions are related ofcourse, for example the expected Kolmogorov Complexity is equal to Shannon entropy).
Darwinian Evolution is a form of Computational Learning
The punchline of this book is perhaps: “Changing or increasing functionality of circuits in biological evolution is a form of computational learning“; although it also speaks of topics other than evolution, the underlying framework is of the Probably Approximately Correct model [1] from the theory of Machine Learning, from which the book gets its name.
“Probably Approximately Correct” by Leslie Valiant
[Clicking on the image above will direct you to the amazon page for the book]
I had first heard of this explicit connection between Machine Learning and Evolution in 2010 and have been quite fascinated by it since. It must be noted, however, that similar ideas have appeared in the past. It won’t be incorrect to say that usually they have been in the form of metaphor. It is another matter that this metaphor has generally been avoided for reasons I underline towards the end of this review. When I first heard about the idea it immediately made sense and like all great ideas, in hindsight looks completely obvious. Ergo, I was quite excited to see this book and preordered it months in advance.
This book is basically a popular science version and expansion of the ideas on the matter that appeared in a J-ACM article titled “Evolvability” in 2007 [2]. I have to say that I was expecting a bit more from the book than what it already had, in this sense I was somewhat disappointed. But at the same time, it can perhaps be a useful ‘starting’ book for those interested in the broad idea but without much background. We all have examples of books like this. Here’s one from me: about a couple of years ago I read a book on Knots by Alexei Sossinsky, the book got bad reviews from many serious mathematicians for not really being about mathematics, besides having many mistakes. But for a complete beginner, I thought it was an absolutely wonderful book, introducing the reader to the basic ideas very informally besides sharing his infectious enthusiasm for problems in Knot Theory. Coming back, in short if you have enough background of the basic notions of PAC Learning then the book might feel quite redundant in some chapters, but depending on how you read, it might still turn out to be a good read any way. Judging from some other (rude) reviews: If you are a professional nitpicker then this book is probably not worth your time since this book deals with ideas and not with a formal treatment of them. Given what it is aiming at, I think it is a good book.
Before attempting to sketch a skiagram of the main content of the book: One of the main subthemes of the book, constantly emphasized is to look at computer science as a kind of an enabling tool to study natural science. This is oft ignored, perhaps because of the reason that CS curricula are rarely designed with any natural science component in them and hence there is no impetus for aspiring computer scientists to view them from the computational lens. On the other hand, the relation of computer science with mathematics has become quite well established. As a technology the impact of Computer Science has been tremendous. All this is quite remarkable given the fact that just about a century ago the notion of a computation was not even well defined. Unrelated to the book: More recently people have started taking the idea of digital physics (i.e. physics from a solely computable/digital perspective) seriously. But in the other natural sciences its usage is still woeful. Valiant draws upon the example of Alan Turing as a natural scientist and not just as a computer scientist to make this point. Alan Turing was more interested in natural phenomenon (intelligence, limits of mechanical calculation, pattern formation etc) and used tools from Computer Science to study them, a fact that is evident from his publications. That Turing was trying to understand natural phenomenon was remarked in his obituary by Max Neumann by summarizing the body of his work as: “the extent and the limitations of mechanistic explanations of nature”.
________________
The book begins with a delightful and quite famous quote by John von Neumann (through this paragraph I also discovered the context to the quote). This paragraph also adequately summarizes the motivation for the book very well:
“In 1947 John von Neumann, the famously gifted mathematician, was keynote speaker at the first annual meeting of the Association for Computng Machinery. In his address he said that future computers would get along with just a dozen instruction types, a number known to be adequate for expressing all of mathematics. He went on to say that one need not be surprised at this small number, since 1000 words were known to be adequate for most situations in real life, and mathematics was only a small part of life, and a very simple part at that. The audience responded with hilarity. This provoked von Neumann to respond: “If people do not believe that mathematics is simple, it is only because they do not realize how complicated life is”
Though counterintuitive, von Neumann’s quip contains an obvious truth. Einstein’s theory of general relativity is simple in the sense that one can write the essential content on one line as a single equation. Understanding its meaning, derivation, and consequences requires more extensive study and effort. However, this formal simplicity is striking and powerful. The power comes from the implied generality, that knowledge of one equation alone will allow one to make accurate predictions about a host of situations not even connected when the equation was first written down.
Most aspects of life are not so simple. If you want to succeed in a job interview, or in making an investment, or in choosing a life partner, you can be quite sure that there is no equation that will guarantee you success. In these endeavors it will not be possible to limit the pieces of knowledge that might be relevant to any one definable source. And even if you had all the relevant knowledge, there may be no surefire way of combining it to yield the best decision.
This book is predicated on taking this distinction seriously […]”
In a way, aspects of life as mentioned above appear theoryless, in the sense that there seems to be no mathematical or scientific theory like relativity for them. Something which is quantitative, definitive and short. Note that these are generally not “theoryless” in the sense that there exists no theory at all since obviously people can do all the tasks mentioned in a complex world quite effectively. A specific example is of how organisms adapt and species evolve without having a theory of the environment as such. How can such coping mechanisms come into being in the first place is the main question asked in the book.
Let’s stick to the specific example of biological evolution. Clearly, it is one of the central ideas in biology and perhaps one of the most important theories in science that changed the way we look at the world. But inspite of its importance, Valiant claims (and correctly in my opinion) that evolution is not understood well in a quantitative sense. Evidence that convinces us of its correctness is of the following sort: Biologists usually show a sequence of evolving objects; stages, where the one coming later is more complex than the previous. Since this is studied mostly via the fossil record there is always a lookout for missing links between successive stages (As a side note: Animal eyes is an extremely fascinating and very readable book that delves with this question but specifically dealing with the evolution of the eye. This is particularly interesting given that due to the very nature of the eye, there can be no fossil records for them). Darwin had remarked that numerous successive paths are necessary – that is, if it was not possible to trace a path from an earlier form to a more complicated form then it was hard to explain how it came about. But again, as Valiant stresses, this is not really an explanation of evolution. It is more of an “existence proof” and not a quantitative explanation. That is, even if there is evidence for the existence of a path, one can’t really say that a certain path is likely to be followed just because it exists. As another side note: Watch this video on evolution by Carl Sagan from the beautiful COSMOS
Related to this, one of the first questions that one might ask, and indeed was asked by Darwin himself: Why has evolution taken as much time as it has? How much time would have sufficed for all the complexity that we see around us to evolve? This question infact bothered Darwin a lot in his day. In On theOrigins of Species he originally gave an estimate of the Earth’s age to be at least 300 million years, implying indirectly, that there was enough time. This estimate was immediately thrashed by Lord Kelvin, one of the pre-eminent British physicists of the time, who estimated the age of the Earth to be only about 24 million years. This caused Darwin to withdraw the estimate from his book. However, this estimate greatly worried Darwin as he thought 24 million years just wasn’t enough time. To motivate on the same theme Valiant writes the following:
“[…] William Paley, in a highly influential book, Natural Theology (1802) , argued that life, as complex as it is, could not have come into being without the help of a designer. Numerous lines of evidence have become available in the two centuries since, through genetics and the fossil record, that persuade professional biologists that existing life forms on Earth are indeed related and have indeed evolved. This evidence contradicts Paley’s conclusion, but it does not directly address his argument. A convincing direct counterargument to Paley’s would need a specific evolution mechanism to be demonstrated capable of giving rise to the quantity and quality of the complexity now found in biology, within the time and resources believed to have been available. […]”
A specific, albeit more limited version of this question might be: Consider the human genome, which has about 3 billion base pairs. Now, if evolution is a search problem, as it naturally appears to be, then why did the evolution of this genome not take exponential time? If it would have taken exponential time then clearly such evolution could not have happened in any time scale since the origin of the earth. Thus, a more pointed question to ask would be: What circuits could evolve in sub-exponential time (and on a related note, what circuits are evolvable only in exponential time?). Given the context, the idea of thinking about this in circuits might seem a little foreign. But on some more thought it is quite clear that the idea of a circuit is natural when it comes to modeling such systems (at least in principle). For example: One might think of the genome as a circuit, just as how one might think of the complex protein interaction networks and networks of neurons in the brain as circuits that update themselves in response to the environment.
The last line is essentially the key idea of adaptation, that entities interact with the environment and update themselves (hopefully to cope better) in response. But the catch is that the world/environment is far too complex for simple entities (relatively speaking), with limited computational power, to have a theory for. Hence, somehow the entity will have to cope without really “understanding” the environment (it can only be partially modeled) and improve their functionality. The key thing to pay attention here is the interaction or the interface between the limited computational entity in question and the environment. The central idea in Valiant’s thesis is to think of and model this interaction as a form of computational learning. The entity will absorb information about the world and “learn” so that in the future it “can do better”.A lot of Biology can be thought of as the above: Complex behaviours in environments. Wherein by complex behaviours we mean that in different circumstances, we (or alternately our limited computational entity) might behave completely differently. Complicated in the sense that there can’t possibly be a look up table for modeling such complex interactions. Such interactions-responses can just be thought of as complicated functions e.g. how would a deer react could be seen as a function of some sensory inputs. Or for another example: Protein circuits. The human body has about 25000 proteins. How much of a certain protein is expressed is a function depending on the quantities of other proteins in the body. This function is quite complicated, certainly not something like a simple linear regression. Thus there are two main questions to be asked: One, how did these circuits come into being without there being a designer to actually design them? Two, How do such circuits maintain themselves? That is, each “node” in protein circuits is a function and as circumstances change it might be best to change the way they work. How could have such a thing evolved?
Given the above, one might ask another question: At what rate can functionality increase or adapt under the Darwinian process? Valiant (like many others, such as Chaitin. See this older blog post for a short discussion) comes to the conclusion that the Darwinian evolution is a very elegant computational process. And since it is so, with the change in the environment there has to be a quantitative way of saying how much rate of change can be kept up with and what environments are unevolvable for the entity. It is not hard to see that this is essentially a question in computer science and no other discipline has the tools to deal with it.
In so far that (biological) interactions-responses might be thought of as complicated functions and that the limited computational entity that is trying to cope has to do better in the future, this is just machine learning! This idea, that changing or increasing functionality of circuits in biological evoution is a form of computational learning, is perhaps very obvious in hindsight. This (changing functionality) is done in Machine Learning in the following sense: We want to acquire complicated functions without explicitly programming for them, from examples and labels (or “correct” answers). This looks at exactly at the question at how complex mechanisms can evolve without someone designing it (consider a simple perceptron learning algorithm for a toy example to illustrate this). In short: We generate a hypothesis and if it doesn’t match our expectations (in performance) then we update the hypothesis by a computational procedure. Just based on a single example one might be able to change the hypothesis. One could draw an analogy to evolution where “examples” could be experiences, and the genome is the circuit that is modified over a period of time. But note that this is not how it looks like in evolution because the above (especially drawing to the perceptron example) sounds more Lamarckian. What the Darwinian process says is that we don’t change the genome directly based on experiences. What instead happens is that we make a lot of copies of the genome which are then tested in the environment with the better one having a higher fitness. Supervised Machine Learning as drawn above is very lamarckian and not exactly Darwinian.
Thus, there is something unsatisfying in the analogy to supervised learning. There is a clear notion of a target in the same. Then one might ask, what is the target of evolution? Evolution is thought of as an undirected process. Without a goal. This is true in a very important sense however this is incorrect. Evolution does not have a goal in the sense that it wants to evolve humans or elephants etc. But it certainly does have a target. This target is “good behaviour” (where behaviour is used very loosely) that would aid in the survival of the entity in an environment. Thus, this target is the “ideal” function (which might be quite complicated) that tells us how to behave in what situation. This is already incorporated in the study of evolution by notions such as fitness that encode that various functions are more beneficial. Thus evolution can be framed as a kind of machine learning problem based on the notion of Darwinian feedback. That is, make many copies of the “current genome” and let the one with good performance in the real world win. More specifically, this is a limited kind of PAC Learning. If you call your current hypothesis your genome, then your genome does not depend on your experiences. Variants to this genome are generated by a polynomial time randomized Turing Machine. To illuminate the difference with supervised learning, we come back to a point made earlier that PAC Learning is essentially Lamarckian i.e. we have a hidden function that we want to learn. One however has examples and labels corresponding to this hidden function, these could be considered “queries” to this function. We then process these example/label pairs and learn a “good estimate” of this hidden function in polynomial time. It is slightly different in Evolvability. Again, we have a hidden “ideal” function f(x). The examples are genomes. However, how we can find out more about the target is very limited, since one can empirically only observe the aggregate goodness of the genome (a performance function). The task then is to mutate the genome so that it’s functionality improves. So the main difference with the usual supervised learning is that one could query the hidden function in a very limited way: That is we can’t act on a single example and have to take aggregate statistics into account.
Then one might ask what can one prove using this model? Valiant demonstrates some examples. For example, Parity functions are not evolvable for uniform distribution while monotone disjunctions are actually evolvable. This function is ofcourse very non biological but it does illustrate the main idea: That the ideal function together with the real world distribution imposes a fitness landscape and that in some settings we can show that some functions can evolve and some can not. This in turn illustrates that evolution is a computational process independent of substrate.
In the same sense as above it can be shown that Boolean Conjunctions are not evolvable for all distributions. There has also been similar work on real valued functions off late which is not reported in detail in the book. Another recent work that is only mentioned in passing towards the end is the study of multidimensional space of actions that deal with sets of functions (not just one function) that might be evolvable together. This is an interesting line of work as it is pretty clear that biological evolution deals with the evolution of a set of functions together and not functions in isolation.
________________
Overall I think the book is quite good. Although I would rate it 3/5. Let me explain. Clearly this book is aimed at the non expert. But this might be disappointing to those who bought the book because of the fact that this recent area of work, of studying evolution through the lens of computational learning, is very exciting and intellectually interesting. The book is also aimed at biologists, and considering this, the learning sections of the book are quite dumbed down. But at the same time, I think the book might fail to impress most of them any way. I think this is because generally biologists (barring a small subset) have a very different way of thinking (say as compared to the mathematicians or computer scientists) especially through the computational lens. I have had some arguments about the main ideas in the book over the past couple of years with some biologist friends who take the usage of “learning” to mean that what is implied is that evolution is a directed process. It would have been great if the book would have spent more time on this particular aspect. Also, the book explicitly states that it is about quantitative aspects of evolution and has nothing to do with speciation, population dynamics and other rich areas of study. However, I have already seen some criticism of the book by biologists on this premise.
As far as I am concerned, as an admirer of Prof. Leslie Valiant’s range and quality of contributions, I would have preferred if the book went into more depth. Just to have a semi-formal monograph on the study of evolution using the tools of PAC Learning right from the person who initiated this area of study. However this is just a selfish consideration.
Long Blurb: In the past year, I read three books by Gregory Chaitin: His magnum opus – MetaMath! (which had been on my reading stack since 2007), a little new book – Proving Darwin and most of Algorithmic Information Theory (available as a PDF as well). Before this I had only read articles and essays by him. I have been sitting on multiple blog post drafts based on these readings but somehow I never got to finishing them up, perhaps it is time to publish them as is! Chaitin is an engaging and provocative writer (and speaker! see this fantastic lecture for instance) who really makes me think. It has come to my notice that a lot of people find his writing style uncomfortable (for apparently lacking humility and having copious hyperbole). While there might be some merits to this view, if one is able to look beyond these minor misgivings he always has a lot of interesting ideas. The apparent hyperbole is best viewed as effusive enthusiasm to get the most out of his writings (since there is indeed a lot to be mined). I might talk about this when I actually write about his books and the ideas therein. For now, this post was in part inspired by something I read in the second book: Proving Darwin.
I thought this was a thought provoking book, but perhaps was not suited to be a book, yet. It builds on the idea of DNA as software and tries to think of Evolution as a random walk in software space. The idea of DNA as software is not new. If one considers DNA to be software and the other biological processes to also be digital, then one is essentially sweeping out all that might not be digital. This view of biological processes might thus be at best an imprecise metaphor. But as Chaitin quotes Picasso ‘art is a lie that helps us see the truth‘ and explains that this is just a model and the point is to see if anything mathematically interesting can be extracted from such a model.
He eloquently points out that once DNA has been thought of as a giant codebase, then we begin to see that a human DNA is just a major software patchwork, having ancient subroutines common with fish, sponges, amphibians etc. As is the case with large software projects, the old code can never be thrown away and has to be reused – patched and made to work and grows by the principle of least effort (thus when someone catches ill and complains of a certain body part being badly designed it is just a case of bad software engineering!). The “growth by accretion” of this codebase perhaps explains Enrst Haeckel‘s slogan “ontogeny recapitulates phylogeny” which roughly means that the growth of a human embryo resembles the successive stages of evolution (thus biology is just a kind of Software Archeology).
All this sounds like a good analogy. But is there any way to formalize this vaguiesh notion of evolution as a random walk in software space and prove theorems about it? In other words, does a theory as elegant as Darwinian Evolution have a purely mathematical core? it must says Chaitin and since the core of Biology is basically information, he reckons that tools from Algorithmic Information Theory might give some answers. Since natural software are too messy, Chaitin considers artificialsoftware in parallel to natural software and considers a contrived toy setting. He then claims in this setting one sees a mathematical proof that such a software evolves. I’ve read some criticisms of this by biologists on the blogosphere, however most criticise it on the premises that Chaitin explicitly states that his book is not about. There are however, some good critiques, I will write about these when I post my draft on the book.
________________
Now coming to the title of the post. The following are some excerpts from the book:
“But we could not realize that the natural world is full of software, we could not see this, until we invented human computer programming languages […] Nobel Laureate Sydney Brenner shared an office with Francis Crick of Watson and Crick. Most Molecular Biologists of this generation credit Schrödinger’s book What is Life? (Cambridge University Press, 1944) for inspiring them. In his autobiography My Life in Science Brenner instead credits von Neumann’s work on self-reproducing automata.
[…] we present a revisionist history of the discovery of software and of the early days of molecular biology from the vantage point of Metabiology […] As Jorge Luis Borges points out, one creates one’s predecessors! […] infact the past is not only occasionally rewritten, it has to be rewritten in order to remain comprehensible to the present. […]
And now for von Neumann’s self reproducing automata. von Neumann, 1951, takes from Gödel the idea of having a description of the organism within the organism = instructions for constructing the organism = hereditary information = digital software = DNA. First you follow the instructions in the DNA to build a new copy of the organism, then you copy the DNA and insert it in the new organism, then you start the new organism running. No infinite regress, no homunculus in the sperm! […]
You see, after Watson and Crick discovered the molecular structure of DNA, the 4-base alphabet A, C, G, T, it still was not clear what was written in this 4-symbol alphabet, it wasn’t clear how DNA worked. But Crick, following Brenner and von Neumann, somewhere in the back of his mind had the idea of DNA as instructions, as software”
I did find this quite interesting, even if it sounds revisionist. That is because the power of a paradigm-shift conceptual leap is often understated, especially after more time has passed. The more time passes, the more “obvious” it becomes and hence the more “diffused” its impact. Consider the idea of a “computation”. A century ago there was no trace of any such idea, but once it was born born and diffused throughout we basically take it for granted. In fact, thinking of a lot of things (anything?) precisely is nearly impossible without the notion of a computation in my opinion. von Neumann often remarked that Turing’s 1936 paper contained in it both the idea of software and hardware and the actual computer was just an implementation of that idea. In the same spirit von Neumann’s ideas on Self-Reproducing automata have had a similar impact on the way people started thinking about natural software and replication and even artificial life (recall the famous von Neumann quote: Life is a process that can be abstracted away from any particular medium).
While I found this proposition quite interesting, I left this at that. Chaitin cited Brenner’s autobiography which I could not obtain since I hadn’t planned on reading it, google-books previews did not suffice either. So i didn’t pursue looking on what Brenner actually said.
However, this changed recently, I exchanged some emails with Maarten Fornerod, who happened to point out an interview of Sydney Brenner that actually talks about this.
The relevant four parts of this very interesting 1984 interview can be found here, here, here and here. The text is reproduced below.
“45: John von Neumann and the history of DNA and self-replication:
What influenced me the most was the articles of von Neumann. Now, I had become interested in von Neumann not through the coding issues but through his interest in the nervous system and computers and of course, that’s what Seymour was interested in because what we wanted to do is find out how the brain worked; that was what… you know, like a hobby on the side, you know. After… after dinner we’d work on central problems of the brain, you see, but it was trying to find out how this worked. And so I got this symposium, the Hixon Symposium, which I had got to read. I was, at that time, very fascinated by a rather strange complexion of psychology things by a man called Wolfgang Köhler who was a gestalt psychologist and another man called Lewin, who was what was called a topological psychologist and of course they were talking at a very different level, but in this book there is an article by Köhler and of course in that book there’s this very famous paper which no one has ever read of von Neumann. Now of course later I discovered that those ideas were much older than the dating of this and that people had taken notes of them and they had circulated. But what is the brilliant part of this paper is in fact his description of what it takes to make a self-reproducing machine. And in fact if you look at what he says and what Schrödinger says, you can see what I have come to call Schrödinger’s fundamental error, and in fact we can… I can find you the passage in that. But it’s an amazing passage, because what von Neumann shows is that you have to have a mechanism not only of copying the machine but of copying the information that specifies the machine, right, so that he then divided the machine – the… the automaton as he called it – into three components: the functional part of the automaton; a… a decoding section of this which is part of that, which actually takes the tape, reads the instructions and builds the automaton; and a device that takes a copy of this tape and inserts it into the new automaton, right, which is the essential… essential, fundamental… and when von Neumann said that is the logical basis of self-reproduction, then you can see where Schrödinger made his mistake and this can be summarised in one sentence. Schrödinger says the chromosomes contain the information to specify the future organism and the means to execute it and that’s not true. The chromosomes contain the information to specify the future organisation and a description of the means to implement, but not the means themselves, and that logical difference is made so crystal clear by von Neumann and that to me, was in fact… The first time now of course, I wasn’t smart enough to really see that this is what DNA is all about, and of course it is one of the ironies of this entire field that were you to write a history of ideas in the whole of DNA, simply from the documented information as it exists in the literature, that is a kind of Hegelian history of ideas, you would certainly say that Watson and Crick depended on von Neumann, because von Neumann essentially tells you how it’s done and then you just… DNA is just one of the implementations of this. But of course, none knew anything about the other, and so it’s a… it’s a great paradox to me that in fact this connection was not seen. Linus Pauling is present at that meeting because he gives this False Theory of Antibodies there. That means he heard von Neumann, must have known von Neumann, but he couldn’t put that together with DNA and of course… well, neither could Linus Pauling put his own paper together with his future work because he and Delbrück wrote a paper on self… on self-complementation – two pieces of information – in about 1949 and had forgotten it by the time he did DNA, so that of course leads to a really distrust about what all the historians of science say, especially those of the history of ideas. But I think that that in a way is part of our kind of revolution in thinking, namely the whole of the theory of computation, which I think biologists have yet to assimilate and yet is there and it’s a… it’s an amazingly paradoxical field. You know, most fields start by struggling through from, from experimental confusion through early theoretical, you know, self-delusion, finally to the great generality and this field starts the other way round. It starts with a total abstract generality, namely it starts with, with Gödel’s hypothesis or the Turing machine, and then it takes, you know, 50 years to descend into… into banality, you see. So it’s the field that goes the other way and that is again remarkable, you know, and they cross each other at about 1953, you know: von Neumann on the way down, Watson and Crick on the way up. It was never put together.
[Q] But… but you didn’t put it together either?
I didn’t put it together, but I did put together a little bit later that, because the moment I saw the DNA molecule, then I knew it. And you connected the two at once? I knew this.
46: Schrodinger Wrong, von Neumann right:
I think he made a fundamental error, and the fundamental error can be seen in his idea of what the chromosome contained. He says… in describing what he calls the code script, he says, ‘The chromosome structures are at the same time instrumental in bringing about the development they foreshadow. They are law code and executive power, or to use another simile, they are the architect’s plan and the builder’s craft in one.’ And in our modern parlance, we would say, ‘They not only contain the program but the means to execute the program’. And that is wrong, because they don’t contain the means; they only contain a description of the means to execute it. Now the person that got it right and got it right before DNA is von Neumann in developing the logic of self-reproducing automata which was based of course on Turing’s previous idea of automaton and he gives this description of this automaton which has one part that is the machine; this machine is built under the instructions of a code script, that is a program and of course there’s another part to the machine that actually has to copy the program and insert a copy in the new machine. So he very clearly distinguishes between the things that read the program and the program itself. In other words, the program has to build the machinery to execute the program and in fact he says it’s… when he tries to talk about the biological significance of this abstract theory, he says: ‘This automaton E has some further attractive sides, which I shall not go into at this time at any length’.
47: Schrodinger’s belief in calculating an organism from chromosomes:
One of the central things in the Schrödinger’s little book What Is Life is what he has to say about the chromosomes containing the program or the code, and he says here… on page 20, he says: ‘In calling the structure of the chromosome fibres a code script, we mean that the all penetrating mind once conceived by Laplace, to which every cause or connection lay immediately open, could tell from their structure whether the egg would develop under suitable conditions, into a black cock, or into a speckled hen, into a fly, or a maize plant, a rhododendron, a beetle, a mouse or a woman’. Now, apart from the list of organisms he has given, which falls short of a serious classification of the living world, what he is saying here is that if you could look at the chromosomes, you could compute the… you could calculate the organism, but he’s saying something more. He’s saying that you could actually implement the organism because he goes on to add: ‘But the term code script is of course too narrow. The chromosome structures are at the same time instrumental in bringing about the development they foreshadow. They are law code and executive power, or to use another simile they are architect’s plan and builder’s craft in one.’ What he is saying here is that the chromosomes not only contain a description of the future organism but the means to implement that description or program as we might call it. That’s wrong, because they don’t contain the means to implement it, they only contain a description of the means to implement it and that distinction was made absolutely crystal clear by this remarkable paper of von Neumann, in which he develops and in fact provides a proof of what a self-reproducing automaton – or machine – would have to… would have to contain in order to satisfy the requirements of self-reproduction. He develops this concept of course from the earlier concept of Turing, who had developed ideas of automata that operated on tapes and which of course gave a mechanical example of how you might implement some computation. And if you like, this is the beginning of the theory of computation and what von Neumann has to say about this is made very clear in this essay. And he says that you’ve got to have several components, and I’ll just summarise them. He said you first start with an automaton A, ‘which, when furnished this description of any other automaton in terms of the appropriate functions, will construct that entity’. It’s like a Turing machine, you see. So automaton A has to be given a tape and then it’ll make another automaton A, all right. Now what you have, you’ve got to have… add to this automaton B. ‘Automaton B can make a copy of any instruction I that is furnished to it’, so if you give it a program, it’ll copy the program. And then you have… you combine A and B with each other and you give a control mechanism C, that you have to add as well, which does the following. It says, ‘Let A be furnished with the instruction I’. So you give… you give the tape to A, A copies it under the control of C, okay, by every description, so it makes another copy of A, then you… and of course B is part of A. Then you… C then tells B, ‘copy this tape I’, gives B the copying part of it, this copies it and then C will then take the tape I, and put it into the new machine, okay, and turns it loose as he says here, ‘as an independent entity’.
48: Automata akin to Living Cells:
What von Neumann says is that you need several components in order to provide this self-reproducing automaton. One component, which he calls automaton A, will make another automaton A when furnished with a description of itself. Then you need an automaton C… you need an automaton B, which has the property of copying the instruction tape I, and then you need a control mechanism which will actually control the switching. And so this automaton, or machine, can reproduce itself in the following way. The entity A is provided with a copy of… with the tape I, it now makes another A. The control mechanism then takes the tape I and gives it to B and says make a copy of this tape. It makes a copy of the tape and the control mechanism then inserts the new copy of the tape into the new automaton and effects the separation of the two. Now, he shows that the entire complex is clearly self-reproductive, there is no vicious circle and he goes on to say, in a very modest way I think, the following. He says, ‘The description of this automaton has some further attractive sides into which I shall not go at this time into any length. For instance, it is quite clear that the instruction I is roughly effecting the functions of a gene. It is also clear that the copying mechanism B performs the fundamental act of reproduction, the duplication of the genetic material which is also clearly the fundamental operation in the multiplication of living cells. It is also clear to see how arbitrary alterations of the system E, and in particular of the tape I, can exhibit certain traits which appear in connection with mutation, which is lethality as a rule, but with a possibility of continuing reproduction with a modification of traits.’ So, I mean, this is… this we know from later work that these ideas were first put forward by him in the late ’40s. This is the… a published form which I read in early 1952; the book was published a year earlier and so I think that it’s a remarkable fact that he had got it right, but I think that because of the cultural difference – distinction between what most biologists were, what most physicists and mathematicians were – it absolutely had no impact at all.”
________________
References and Also See:
1. Proving Darwin: Making Biology Mathematical, Gregory Chatin (Amazon).
2. Theory of Self-Reproducing Automata, John von Neumann. (PDF).
On June 23 last year ACM organized a special event to celebrate the birth centenary of Alan Turing with 33 Turing award winners in attendance. Needless to say most of the presentations, lectures and discussions were quite fantastic. They had been placed as webcasts on this website, however rather unfortunately, they were not individually linkable and it was difficult to share them. I noticed day before yesterday that they were finally available on youtube!
One particular video that I had liked a lot was “An Algorithmic View of the Universe”, featuring some great discussions between a panel comprising of Robert Tarjan, Richard Karp, Don Knuth, Leslie Valiant and Leonard Adleman, with the panel chaired by Christos Papadimitriou. You might want to consider watching it if you have about 80 minutes to spare and provided you haven’t watched it earlier!
John von Neumann made so many fundamental contributions that Paul Halmos remarked that it was almost like von Neumann maintained a list of various subjects that he wanted to touch and develop and he systematically kept ticking items off. This sounds to be remarkably true if one just has a glance at the dizzyingly long “known for” column below his photograph on his wikipedia entry.
John von Neumann with one of his computers.
Since Neumann died (young) in 1957, rather unfortunately, there aren’t very many audio/video recordings of his (if I am correct just one 2 minute video recording exists in the public domain so far).
I recently came across a fantastic film on him that I would very highly recommend. Although it is old and the audio quality is not the best, it is certainly worth spending an hour on. The fact that this film features Eugene Wigner, Stanislaw Ulam, Oskar Morgenstern, Paul Halmos (whose little presentation I really enjoyed), Herman Goldstein, Hans Bethe and Edward Teller (who I heard for the first time, spoke quite interestingly) alone makes it worthwhile.
Update: The following youtube links have been removed for breach of copyright. The producer of the film David Hoffman, tells us that the movie should be available as a DVD for purchase soon. Please check the comments to this post for more information.
Changing or increasing functionality of circuits in biological evolution is a form of computational learning. – Leslie Valiant
The title of this post comes from Prof. Leslie Valiant‘s The ACM Alan M. Turing award lecture titled “The Extent and Limitations of Mechanistic Explanations of Nature”.
Short blurb: Though the lecture came out sometime in June-July 2011, and I have shared it (and a paper that it quotes) on every online social network I have presence on, I have no idea why I never blogged about it.
The fact that I have zero training (and epsilon knowledge of) in biology that has not stopped me from being completely fascinated by the contents of the talk and a few papers that he cites in it. I have tried to see the lecture a few times and have also started to read and understand some of the papers he mentions. Infact, the talk has inspired me enough to know more about PAC Learning than the usual Machine Learning graduate course might cover. Knowing more about it is now my “full time side-project” and it is a very exciting side-project to say the least!
_________________________
Getting back to the title: One of the motivating questions about this work is the following:
It is widely accepted that Darwinian Evolution has been the driving force for the immense complexity observed in life or how life evolved. In this beautiful 10 minute video Carl Sagan sums up the timeline and the progression:
There is however one problem: While evolution is considered the driving force for such complexity, there isn’t a satisfactory explanation of how 13.75 billion years of it could have been enough. Many have often complained that this reduces it to a little more than an intuitive explanation. Can we understand the underlying mechanism of Evolution (that can in turn give reasonable time bounds)? Valiant makes the case that this underlying mechanism is of computational learning.
There have been a number of computational models that have been based on the general intuitive idea of Darwinian Evolution. Some of these include: Genetic Algorithms/Programming etc. However, people like Valiant amongst others find such methods useful in an engineering sense but unsatisfying w.r.t the question.
In the talk Valiant mentions that this question was asked in Darwin’s day as well. To which Darwin proposed a bound of 300 million years for such evolution to occur. This immediately fell into a problem as Lord Kelvin, one of the leading physicists of the time put the figure of the age of Earth to be 24 million years. Now obviously this was a problem as evolution could not have happened for more than 24 million years according to Kelvin’s estimate. The estimate of the age of the Earth is now much higher. ;-)
The question can be rehashed as: How much time is enough? Can biological circuits evolve in sub-exponential time?
Towards the end of the talk he shows a Venn diagram of the type usually seen in complexity theory text books for classes P, NP, BQP etc but with one major difference: These subsets are fact and not unproven:
*SQ or Statistical Query Learning is due to Michael Kearns (1993)
Coda: Valiant claims that the problem of evolution is no more mysterious than the problem of learning. The mechanism that underlies biological evolution is “evolvable target pursuit”, which in turn is the same as “learnable target pursuit”.
One interesting project that I am involved in these days involves certain problems in Intelligent Tutors. It turns out that perhaps one of the best ways to tackle them is by using Conditional Random Fields (CRFs). Many attempts to solving these problems still involve Hidden Markov Models (HMMs). Since I have never really been a Graphical Models guy (though I am always fascinated) so I found the going on studying CRFs quite difficult. Now that the survey is more or less over, here are my suggestions for beginners to go about learning them.
Tutorialsand Theory
1.Log-Linear Models and Conditional Random Fields (Tutorial by Charles Elkan)
Log-linear Models and Conditional Random Fields Charles Elkan
6 videos: Click on Image above to view
Two directions of approaching CRFs are especially useful to get a good perspective on their use. One of these is considering CRFs as an alternate to Hidden Markov Models (HMMs) while another is to think of CRFs building over Logistic Regression.
This tutorial makes an approach from the second direction and is easily one of the most basic around. Most people interested in CRFs would ofcourse be familiar with ideas of maximum likelihood, logistic regression etc. This tutorial does a good job, starting with the absolute basics – talking about logistic regression (for a two class problem) to a more general multi-label machine learning problem with a structured output (outputs having a structure). I tried reading a few tutorials before this one, but found this to be the most comprehensive and the best place to start. It however seems that there is one lecture missing in this series which (going by the notes) covered more training algorithms.
2. Survey Papers on Relational Learning
These are not really tutorials on CRFs, but talk of sequential learning in general. For beginners, these surveys are useful to clarify the range of problems in which CRFs might be useful while also discussing other methods for the same briefly. I would recommend these two tutorials to help put CRFs in perspective in the broader machine learning sub-area of Relational Learning.
— Machine Learning for Sequential Learning: A Survey (Thomas Dietterich)
This tutorial is like the above, however focuses more on comparing CRFs with large margin methods such as SVM. Giving yet another interesting perspective in placing CRFs.
This tutorial is the most compendious tutorial available for CRF. While it claims to start from the bare bone basics, I found it hard for a start and took it on third (after the above two). It is potentially the starting and ending point for a more advanced Graphical Models student. It is extensive (90 pages) and gives a feeling of comfort with CRFs when done. It is definitely the best tutorial available though by no means the most easiest point to start if you have never done any sequential learning before.
This report is good for the various training methods and for one to go through the derivations associated.
6. Applications to Vision (Nowozin/Lampert)
If your primary focus is using structured prediction in Computer Vision/Image Analysis then a good tutorial (with a large section on CRFs) can be found over here:
Structured prediction and learning in Computer Vision (Foundations and Trends Volume).
2. MALLET (I haven’t used MALLET, it is Java based)
3. HCRF – LDCRF Library (MATLAB, C++, Python). As as the name suggests, this package is for HCRF and LDCRF, though can be used as a standalone package for CRF as well.
For the past couple of years, I have had a couple of questions about machine learning research that I have wanted to ask some experts, but never got the chance to do so. I did not even know if my questions made sense at all. I would probably write about them on a blog post soon enough.
It is however ironical that I came to know my questions were valid and well discussed (I never knew what to search for them, I used expressions not used by researchers) only by the death of Ray Solomonoff (he was one researcher who worked on it, and an obituary on him highlighted his work on it, something I missed). Solomonoff was one of the founding fathers of Artificial Intelligence as a field and Machine Learning as a discipline within it. It must be noted that he was one of the few attendees at the 1956 Dartmouth Conference, basically an extended brain storming session that started AI formally as a field. The other attendees were : Marvin Minsky, John McCarthy, Allen Newell, Herbert Simon, Arthur Samuel, Oliver Selfridge,Claude Shannon, Nathaniel Rochester and Trenchand Moore. His 1950-52 papers on networks are regarded as the first statistical analysis of the same. Solomonoff was thus a towering figure in AI and Machine Learning.
[Ray Solomonoff : (25 July 1926- 7 December 2009)]
Solomonoff is widely considered as the father of Machine Learning for circulating the first report on the same in 1956. His particular focus was on the use of probability and its relation to learning. He founded the idea of Algorithmic Probability (ALP) in a 1960 paper at Caltech, an idea that gives rise to Kolmogorov Complexity as a side product. A. N. Kolmogorov independently discovered similar results and came to know of and acknowledged Solomonoff’s earlier work on Algorithmic Information Theory. His work however was relatively unknown in the west than in the soviet union, which is why Algorithmic Information Theory is mostly referred to as Kolmogorov complexity rather than “Solomonoff Complexity”. Kolmogorov and Solomonoff approached the same framework from different directions. While Kolmogorov was concerned with randomness and Information Theory, Solomonoff was concerned with inductive reasoning. And in doing so he discovered ALP and Kolomogorov Complexity years before anyone did. I would write below on only one aspect of his work that I have studied to some degree in the past year.
Solomonoff With G.J Chaitin, another pioneer in Algorithmic Information Theory
His 1956 paper, “An inductive inference machine” was one of the seminal papers that used probability in Machine Learning. He outlined two main problems which he thought (correctly) were linked.
The Problem of Learning in Humans : How do you use all the information that you gather in life in making decisions?
The Problem of Probability : Given you have some data and some a-priori information, how can you make the best possible predictions for the future?
The problem of learning is more general and related to the problem of probability. Solomonoff noted that the Machine learning was simply the process of approximating ideal probabilistic predictions for practical use.
Building on his 1956 paper, he discovered probabilistic languages for induction at a time when it was considered out of fashion. And discovered the Universal Distribution.
All induction problems could be basically reduced to this form : Given a sequence of binary symbols how do you extrapolate it? The answer being that we could assign a probability to a sequence and then use Bayes Theorem to make a prediction on which particular continuation of a string was how likely. That gives rise to an even more difficult question that was the basic question for a lot of Solomonoff’s work and on Algorithmic Probability/Algorithmic Information Theory. This question is : How do you assign probabilities to strings?
Solomonoff approached this problem using the idea of a Universal Turing Machine. Suppose this Turing Machine has three types of tapes, an unidirectional input tape, an unidirectional output tape and a bidirectional working tape. Suppose this machine will take some binary string as input and it may give a binary string as output.
It could do any of the following :
1. Print out a string after a while and then come to a stop.
2. It could print an infinite output string.
3. It could go in an infinite loop for computing the string and not output anything at all (Halting Problem).
For a string , the ALP would be as follows :
If we feed some bits at random to our Turing Machine, there will always be some probability that the output would start with a string . This probability is the algorithmic or universal probability of the string .
The ALP would be given as :
Where would be the universal probability of string with respect to the universal turing machine . To understand the placement of in the above expression, let’s discuss it a little.
There could be many random strings that after being processed by the Turing Machine give an output string that begins with string . And is the such string. Each such string carries a description of . And since we want to consider all cases, we take the summation. In the expression above gives the length of a string and the probability that the random input would output a string starting with .
This definition of ALP has the following properties that have been stated and proved by Solomonoff in the 60s and the 70s.
1. It assigns higher probabilities to strings with shorter descriptions. This is the reverse of something like Huffman Coding.
2. The value for ALP would be independent of the type of the universal machine used.
3. ALP is incomputible. This is the case because of the halting problem. Infact it is this reason that it has not received much attention. Why get interested in a model that is incomputible? However Solomonoff insisted that approximations to the ALP would be much better than existing systems and that getting the exact ALP is not even needed.
4. is a complete description for . That means any pattern in the data could be found by using . This means that the universal distribution is the only inductive principle that is complete. And approximations to it would be much desirable.
__________
Solomonoff also worked on Grammar discovery and was very interested in Koza’s Genetic Programming system, which he believed could lead to efficient and much better machine learning methods. He published papers till the ripe old age of 83 and is definitely inspiring for the love of his work. Paul Vitanyi notes that :
It is unusual to find a productive major scientist that is not regularly employed at all. But from all the elder people (not only scientists) I know, Ray Solomonoff was the happiest, the most inquisitive, and the most satisfied. He continued publishing papers right up to his death at 83.
Solomonoff’s ideas are still not exploited to their full potential and in my opinion would be necessary to explore to build the Machine Learning dream of never-ending learners and incremental + synergistic Machine Learning. I would write about this in a later post pretty soon. It was a life of great distinction and a life well lived. I also wish strength and peace to his wife Grace and his nephew Alex.
The five surviving (in 2006) founders of AI who met in 2006 to commemorate 50 years of the Dartmouth Conference. From left : Trenchand Moore, John McCarthy, Marvin Minsky, Oliver Selfridge and Ray Solomonoff
Here are a number of interesting courses, two of which I am looking at for the past two weeks and that i would hopefully finish by the end of August-September.
Introduction to Neural Networks (MIT):
These days, amongst the other things that I have at hand including a project on content based image retrieval. I have been making it a point to look at a MIT course on Neural Networks. And needless to say, I am getting to learn loads.
I would like to emphasize that though I have implemented a signature verification system using Neural Nets, I am by no means good with them. I can be classified a beginner. The tool that I am more comfortable with are Support Vector Machines.
I have been wanting to know more about them for some years now, but I never really got the time or you can say the opportunity. Now that I can invest some time, I am glad I came across this course. So far I have been able to look at 7 lectures and I should say that I am MORE than very happy with the course. I think it is very detailed and extremely well suited for the beginner as well as the expert.
The instructor is H. Sebastian Seung who is the professor of computational neuroscience at the MIT.
The course has 25 lectures each one packed with a great amount of information. Meaning, the lectures might work slow for those who are not very familiar with this stuff.
The video lectures can be accessed over here. I must admit that i am a little disappointed that these lectures are not available on you-tube. That’s because the downloads are rather large in size. But I found them worth it any way.
The lectures cover the following:
Lecture 1: Classical neurodynamics Lecture 2: Linear threshold neuron Lecture 3: Multilayer perceptrons Lecture 4: Convolutional networks and vision Lecture 5: Amplification and attenuation Lecture 6: Lateral inhibition in the retina Lecture 7: Linear recurrent networks Lecture 8: Nonlinear global inhibition Lecture 9: Permitted and forbidden sets Lecture 10: Lateral excitation and inhibition Lecture 11: Objectives and optimization Lecture 12: Excitatory-inhibitory networks Lecture 13: Associative memory I Lecture 14: Associative memory II Lecture 15: Vector quantization and competitive learning Lecture 16: Principal component analysis Lecture 17: Models of neural development Lecture 18: Independent component analysis Lecture 19: Nonnegative matrix factorization. Delta rule. Lecture 20: Backpropagation I Lecture 21: Backpropagation II Lecture 22: Contrastive Hebbian learning Lecture 23: Reinforcement Learning I Lecture 24: Reinforcement Learning II Lecture 25: Review session
The good thing is that I have formally studied most of the stuff after lecture 13 , but going by the quality of lectures so far (first 7), I would not mind seeing them again.
This is a Harvard course. I don’t know when I’ll get the time to have a look at this course, but it sure looks extremely interesting. And I am sure a number of people would be interested in having a look at it. It looks like a course that be covered up pretty quickly actually.
The amount and complexity of information produced in science, engineering, business, and everyday human activity is increasing at staggering rates. The goal of this course is to expose you to visual representation methods and techniques that increase the understanding of complex data. Good visualizations not only present a visual interpretation of data, but do so by improving comprehension, communication, and decision making.
In this course you will learn how the human visual system processes and perceives images, good design practices for visualization, tools for visualization of data from a variety of fields, collecting data from web sites with Python, and programming of interactive visualization applications using Processing.
This is one course that I would be looking at some parts of after I have covered the course on Neural Nets. I am yet to glance at the first lecture or the materials, so i can not say how they would be like. But I sure am expecting a lot from them going by the topics they are covering.
I don’t know if I would be able to squeeze in time for these. But because of my amateurish interest in chemistry (If I were not an electrical engineer, I would have been into Chemistry), and because I have very high regard for Dr Harry Kroto (who is delivering them) I would try and make it a point to have a look at them. I think I’ll skip gym for some days to have a look at them. ;-)
[Nobel Laureate Harry Kroto with a Bucky-Ball model – Image Source : richarddawkins.net]
While searching for some methods for face representation in connection with my recent project, I lost the way clicking on some stray links and landed up on some beautiful art work involving Voronoi diagrams. I was aware of art work based on Voronoi diagrams (it kind of follows naturally that Voronoi diagrams can lead to very elegant designs, isn’t it?) but a couple of images on them were enough to re-ignite interest. It was also interesting to see an alternate solution to my problem based on Voronoi diagrams as well. However I intend to share some of the art work I came across.
———-
Before I get to the actual art-work I suppose it would be handy to give a very basic introduction to Voronoi Diagrams with a couple of handy applications.
Introduction: Voronoi diagrams are named after Georgy Voronoy (1868-1908), an eminent Russian/Ukrainian mathematician. A number of mathematicians before Voronoy such as Descartes and Dirichlet have been known to have used them, Voronoy extended the idea to dimensions. The Voronoi diagram is a tessellation, or a tiling. A tiling of a plane is simply a collection of plane figures that fills the plane with no overlaps and no gaps in between. This idea can ofcourse be extended to dimensions, but for simplicity let us stick with 2 dimensions.
[A pavement Tessellation/Tiling]
Definition: A Voronoi diagram is a special kind of a decomposition of a metric space which is determined by a discrete set of points.
Generally speakingfor a 2-D case:
>> Let us designate a set of distinct points that we call sites as . i.e
>> We may then define the Voronoi Diagram of P as a collection of subsets of the plane. These subsets are called as Voronoi Regions. Each point in is such that it is closer to than any other point in .
To be more precise:
A point lies in the Voronoi Regioncorresponding to a site if and only if –
for each
However it might be the case that there are some points in the plane that might have more than one site that is the closest to it. These points do not lie in either Voronoi Region, but simply lie on the boundary of two adjacent regions. All such points form a skeleton of lines that is called the Voronoi Skeletonof .
We can say that is the Voronoi Transform, that transforms a set of discrete points (sites) into a Voronoi Diagram.
———-
For more clarity on the above, consider a sample Voronoi Diagram below:
The dots are called the Sites. The Voronoi Regionsare simply areas around a site but enclosed by the lines around them. The network of lines is simply the Voronoi Skeleton.
———-
Some Extensions to the above Definition: The above definition which is ofcourse extremely simple can be extended very easily[1] for getting some fun art forms.
Some of these extensions could be as follows [1]:
1. Since each region corresponds to a site, each site can be associated with a color. Hence the Voronoi diagram can be colored accordingly.
2. In the definition the sites were considered to be simply points, we can obtain a variety of figures by allowing the “sites” to be subsets of the plane than just points. We see, that if the sites are defined as simply points, the Voronoi skeleton would always be composed of straight lines. With this change there could be interesting skeletal figures emerging.
3. We could also modify the distance metric from the Euclidean distance to some other to get some very interesting figures.
This just shows the kind of variety of figures that can be generated by just a small change in one aspect of the basic definition.
———-
Constructing a Voronoi Diagram:
Let us forget the extensions that we spoke of for a moment and come back to the basic definition. Looking at the definition it seems constructing Voronoi diagrams is a simple process. And it is not difficult at all. The steps are as follows:
1. Consider a random set of points.
2. Connect ALL of these points by straight lines.
3. Draw a perpendicular bisector to EACH of these connecting lines.
4. Now select pieces that are formed, such that each site (point) is encapsulated.
Voronoi Diagrams can be very easily made by direct commands in both MATLAB and MATHEMATICA.
———-
Voronoi Diagrams in Nature: It is interesting to see how often Voronoi diagrams occur in nature. Just consider two examples:
[Left: Reticulum Plasmatique (Image Source) Right: Polygons on Giraffes]
———-
Uses of Voronoi Diagrams: There are a wide variety of applications of Voronoi diagrams. They are more important then what one might come to believe. Some of the applications are as follows:
1. Nearest Neighbour Search: This is the most obvious application of Voronoi Diagrams.
2. Facility Location: The example that is often quoted in this case is the example of choosing where to place a new Antenna in case of cellular mobile systems and similarly deciding the location of a new McDonalds given a number of them already exist in the city.
3. Path Planning: Suppose one models the sites as obstacles, then they can be used to determine the best path (a path that stays at a maximum distance from all obstacles or sites).
There are a number of other applications, such as in Geophysics, Metrology, Computer Graphics, Epidemiology and even pattern recognition. A very good example that illustrates how they can be used was the analysis of the Cholera epidemic in London in 1854, in which physician John Snow determined a very strong correlation of deaths with proximity to a particular infected pump (specific example from Wolfram Mathworld).
Let’s consider the specific example of path planning [2]. Consider a robot placed in one corner of a room with stuff dispersed around.
Now the best path from the point where the robot is located to the goal would be the one in which the robot is farthest from the nearest obstacle at any point in time. To find such a path, the Voronoi diagram of the room would be required to be found out. Once it is done, the vertices or the skeleton of the Voronoi Diagram provides the best path. Which path ultimately is to be taken can be found out by comparing the various options (alternative paths) by using search algorithms.
Now finally after the background on Voronoi Diagrams let’s look at some cool artwork that i came across. ;-)
———-
Fractals from Voronoi Diagrams:
This I came across on the page of Kim Sherriff[3]. The idea is straightforward to say the least.
It is: To create a fractal, first create a Voronoi diagram from some points, next add more points and then create the Voronoi diagrams inside individual Voronoi Regions. Some sample progression could be like this:
I am really going to try this myself, it seems a few hours of work at first sight. Ofcourse I won’t use the code that the author has provided. ;-)
———-
Mosaic Images Using Voronoi Diagrams[5]:
I have not had the time to read this paper. However, I am always attracted by mosaics, and these ones (the ones in the paper) as created using Voronoi Diagrams have an increased coolness quotient for me. Sample this image:
Golan Levin’s[6] experiments in using Voronoi diagrams to obtain aesthetic forms yielded probably even more pleasant results. The ones below give a very delicate look to their subjects.
The tilings that are produced by just mild tweaks to the basic definition of a Voronoi Diagram for a 2-D case that I had talked about earlier can give rise to a variety of tilings. Say like the one below:
One of the favorite maxims of my father was the distinction between the two sorts of truths, profound truths recognized by the fact that the opposite is also a profound truth, in contrast to trivialities where opposites are obviously absurd.







 , the ALP would be as follows :
, the ALP would be as follows :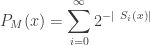
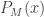 would be the universal probability of string
would be the universal probability of string  . To understand the placement of
. To understand the placement of 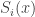 in the above expression, let’s discuss it a little.
in the above expression, let’s discuss it a little.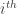 such string. Each such string carries a description of
such string. Each such string carries a description of 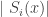 gives the length of a string and
gives the length of a string and  the probability that the random input
the probability that the random input  would output a string starting with
would output a string starting with  . This means that the universal distribution is the only inductive principle that is complete. And approximations to it would be much desirable.
. This means that the universal distribution is the only inductive principle that is complete. And approximations to it would be much desirable.



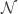 dimensions. The Voronoi diagram is a
dimensions. The Voronoi diagram is a 
 distinct points that we call sites as
distinct points that we call sites as 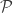 . i.e
. i.e 
 of subsets of the plane. These subsets are called as Voronoi Regions. Each point in
of subsets of the plane. These subsets are called as Voronoi Regions. Each point in  is such that it is closer to
is such that it is closer to 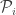 than any other point in
than any other point in  lies in the Voronoi Region corresponding to a site
lies in the Voronoi Region corresponding to a site 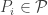 if and only if –
if and only if – for each
for each 
 is the Voronoi Transform, that transforms a set of discrete points (sites) into a Voronoi Diagram.
is the Voronoi Transform, that transforms a set of discrete points (sites) into a Voronoi Diagram.















