The Jacobian Inner Product
August 20, 2014 by Shubhendu Trivedi
This post may be considered an extension of the previous post.
The setup and notation is the same as in the previous post (linked above). But to summarize: Earlier we had an unknown smooth regression function 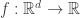 . The idea was to estimate at each training point, the gradient of this unknown function
. The idea was to estimate at each training point, the gradient of this unknown function  , and then taking the sample expectation of the outerproduct of the gradient. This quantity has some interesting properties and applications.
, and then taking the sample expectation of the outerproduct of the gradient. This quantity has some interesting properties and applications.
However it has its limitations, for one, the mapping restricts the Gradient Outer Product being helpful for only regression and binary classification (since for binary classification the problem can be thought of as regression). It is not clear if a similar operator can be constructed when one is dealing with classification, that is the unknown smooth function is a vector valued function 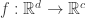 where
where  is the number of classes (let us say for the purpose of this discussion, that for each data point we have a probability distribution over the classes, a dimensional vector).
is the number of classes (let us say for the purpose of this discussion, that for each data point we have a probability distribution over the classes, a dimensional vector).
In the case of the gradient outer product since we were working with a real valued function, it was possible to define the gradient at each point, which is simply:
![\displaystyle \Bigg[ \frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, \dots, \frac{\partial f}{\partial x_d} \Bigg]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CBigg%5B+%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+x_1%7D%2C+%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+x_2%7D%2C+%5Cdots%2C+%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+x_d%7D+%5CBigg%5D&bg=ffffff&fg=333333&s=0&c=20201002)
For a vector valued function , we can’t have the gradient, but instead can define the Jacobian at each point:
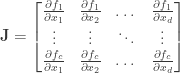
Note that 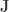 may be estimated in a similar manner as estimating gradients as in the previous posts. Which leads us to define the quantity
may be estimated in a similar manner as estimating gradients as in the previous posts. Which leads us to define the quantity 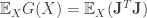 .
.
The first thing to note is that 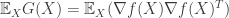 defined in the previous post is simply the quantity for the special case when . Another note is also in order: The reason why we suffixed that quantity with “outer product” (as opposed to “inner product” here) is simply because we considered the gradient to be a column vector, otherwise they are similar in spirit.
defined in the previous post is simply the quantity for the special case when . Another note is also in order: The reason why we suffixed that quantity with “outer product” (as opposed to “inner product” here) is simply because we considered the gradient to be a column vector, otherwise they are similar in spirit.
Another thing to note is that it is easy to see that the quantity is a positive semi-definite matrix and hence is a Reimannian Metric, which is defined below:
Definition: A Reimannian Metric  on a manifold
on a manifold 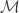 is a symmetric and positive semi-definite matrix, which defines a smoothly varying inner product in the tangent space
is a symmetric and positive semi-definite matrix, which defines a smoothly varying inner product in the tangent space 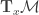 , for each point
, for each point 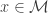 and
and 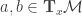 . This associated p.s.d matrix is called the metric tensor. In the above case, since is p.s.d it defines a Reimannian metric:
. This associated p.s.d matrix is called the metric tensor. In the above case, since is p.s.d it defines a Reimannian metric:

Thus, 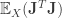 is a specific metric (more general metrics are dealt with in areas such as metric learning).
is a specific metric (more general metrics are dealt with in areas such as metric learning).
Properties: We saw some properties of in the previous post. In the same vein, does have similar properties? i.e. does the first eigenvector also correspond to the direction of highest average variation? What about the  -dimensional subspace? What difference does it make that we are looking at a vector valued function? Also what about the cases when
-dimensional subspace? What difference does it make that we are looking at a vector valued function? Also what about the cases when  and otherwise?
and otherwise?
These are questions that I need to think about and should be the topic for a future post to be made soon, hopefully.





[…] Implementation and Abstraction in Mathematics The Jacobian Inner Product […]