Note: The title of this post is circular. But I use/abuse it because of the post linked below.
I noticed on the Hacker News front page (and via multiple reshares on twitter), a discussion on why logistic regression uses a sigmoid. The article linked in the story talks about the log-odds ratio, and how it leads to the sigmoid (and gives a good intuitive plug on it).
However, I think that the more important question is – Why do you care about log-odds? Why do you use log-odds and not something else? The point of this quick post is to write out why using the log-odds is infact very well motivated in the first place, and once it is modeled by a linear function, what you get is the logistic function.
Beginning with log-odds would infact be begging the question, so let us try to understand.
____________________________
To motivate and in order to define the loss etc, suppose we had a linear classifier: 
The learning problem would be to figure out a good direction 
____________________________
We want to figure these out so as to minimize the expected 0-1 loss (or expected number of mistakes) for the classifier 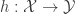
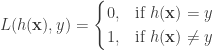
Now, the next question we would like to ask. What is the risk of this classifier that we want to minimize? The risk is the expected loss. That is, if we draw a random sample from the (unknown) distribution 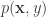
![R(h) = \mathbb{E}_{\mathbf{x},y} [L(h(\mathbf{x}),y)]](https://s0.wp.com/latex.php?latex=R%28h%29%C2%A0+%3D+%5Cmathbb%7BE%7D_%7B%5Cmathbf%7Bx%7D%2Cy%7D+%5BL%28h%28%5Cmathbf%7Bx%7D%29%2Cy%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Writing out the expectation:
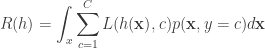
Using the chain rule this becomes:
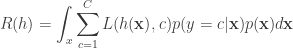
It is important to understand this expression. This is not assuming anything about the data. However, it is this expression that we want to minimize if we want to get a good classifier. To minimize this expression, it suffices to simply minimize for the conditional risk for any point 
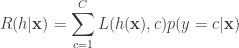
But this conditional risk can be written as:

Note that,
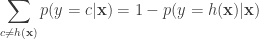
Therefore, the conditional risk is simply:

Now, it is this conditional risk that we want to minimize given a point
It is again important to note that so far we have made absolutely no assumptions about the data. So the above classifier is the best classifier that we can have in terms of generalization, in the sense of what might be the expected loss on a new sample point. Such a classifier is called the Bayes Classifier or sometimes called the Plug-in classifier.
But the optimal decision rule mentioned above i.e. 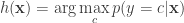
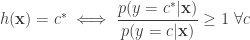
by taking log, this would be:
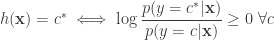
If, we were only dealing with binary classification, this would imply:
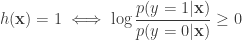
Notice that by making no assumptions about the data, simply by writing out the conditional risk, the log-odds ratio has fallen out directly. This is not an accident, because the optimal bayes classifier has this form for binary classification. But the question still remains, how do we model this log-odds ratio? The simplest option is to consider a linear model (there is no reason to stick to a linear model, but due to some reasons, one being convexity, we stick to a linear model):

Now, we know that 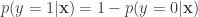
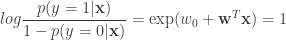
Rearranging, yields the familiar logistic model (and the sigmoid):

As noted in the post linked in the beginning, the logistic model, 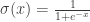

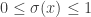
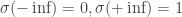
____________________________
This derivation shows that the log-odds is not an arbitrary choice, infact a very natural choice. The sigmoid is simply a consequence of modeling the log-odds with a linear function (infact logistic regression is arguably the simplest example of a log-linear model, if we had structured outputs, a natural extension of such a model would be the Conditional Random Field. The choice of using a linear function is simply to make the optimization convex, amongst some other favourable properties).
____________________________
Note: This post was inspired by some very succinct notes by Gregory Shakhnarovich from his Machine Learning class, that I both took and served as a TA for.





{kind=link}
{kind=link}
It falls out naturally using the maximum entropy approach.
But this doesn’t seem to answer the actual question. Your mapping of the conditional risk for y=c to the conditional odds of y=c is the key point, but it’s an arbitrary step. The same mapping could be made for any monotonic transformation of the risk, such as a probit function or simply a log-function. The reason for going to the log-odds, historically, is that, unlike a linear risk model, the parameters of the classifier are not bound by [0,1] and unlike the log-risk model, it’s not bound above. The parameters of a linear-logistic model (and probit) live on (-infty,infty), so computational algorithms have an easy time coming up with a solution that converges. That’s the real reason for using logistic versus, say, a linear or log-linear risk model. This just seems like a lot of hand-waving around why the logistic function is chosen versus any other arbitrary monotonic transformation of the optimal decision rule.
I am aware of what you are saying, however I don’t think that was the point of the post, while making the post I thought about it and decided to not write about it. I think the main point was to show how the logistic falls off when you write down the Bayes risk. I do mention in passing both the efficiency considerations and that one could use any other likn function. Also, I don’t see how the mapping to the odds is arbitrary.
Great post! Just one comment though: There are typos in your steps when you are assuming the log-odds as a linear function and carrying on the rest of the derivations.
Cheers!