I am often asked by some interested friends : What ARE actually support vector machines? What kind of machines? It is obvious that such questions are put up by people who are not initiated to the idea of SVMs or even learning machines so to say.
But I have also noticed that a lot of people working in the ML/AI/Pattern Recognition domain don’t have a clear idea of why Support Vector Machines are called so. Understanding why Artificial Neural Networks are named so is not so difficult, but Support Vector Machines does sound somewhat abstruse. This is exactly what this post aims to address.
I’d be giving a short introduction first. For those who simply wish to get to the point, I would recommend them to skip to this point.
Let’s parse SVM into the three constituent words and attack them one by one – Support Vector Machines. Let’s look at Machines first.
_____
Learning Machines: Clearly this part is meant for the former category in the two I mentioned in the above introductory paragraph i.e for the uninitiated.
Let me start with a basic definition that I think is necessary to be put for the sake of mere completeness. I hope this does not disgust the more expert reader. ;-)
Machine Learning
Way back in 1959, Arthur Samuel defined Machine Learning as the field of study that gave computers the ability to learn without being explicitly programmed. Samuel was a pioneer in the area as he is widely credited to have made the first self-learning program that played checkers.
Tom Mitchell in Machine Learning puts the definition more formally as: A learning program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
Given a training set, we feed it into a learning algorithm (like SVM, Artificial Neural Nets, Logistic Regression, Linear Regression etc). The learning algorithm then outputs a function, which for historical reasons is called the hypothesis and denoted by 

So, basically the hypothesis’ job is to take a new input and give out a estimated output or class. The parameters that define the hypothesis are what are “learned” by using the training set. So the term learning machine is used in this sense.
To sum up: The hypothesis can be thought of as a machine that gives a prediction y on some unseen input x. The parameters of the hypothesis are learned (for a toy example see the part on pigeons in this post).
Ofcourse the above is defined in a supervised context but can be easily generalized.
_____
Support Vector Machines
An Introduction: I would prefer to give an extremely short introduction to SVMs first before coming to the origin of the term “Support Vectors”.
Consider the image below. How would you classify this data?
 This set looks linearly separable. That means we could draw a straight line to separate the two classes (indicated by the two different colors). Also note that these data points lie in a two dimensional space, so we talk of a straight line. We could easily graduate to higher dimensions, as an example in a 3-D space we would have spoken of constructing a plane to separate the points and a hyperplane in a
This set looks linearly separable. That means we could draw a straight line to separate the two classes (indicated by the two different colors). Also note that these data points lie in a two dimensional space, so we talk of a straight line. We could easily graduate to higher dimensions, as an example in a 3-D space we would have spoken of constructing a plane to separate the points and a hyperplane in a 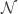
Coming back, though we can draw a straight line to separate these two classes, there is a problem. There are an infinite number of candidate lines. Which straight line to choose?

There are two intuitions that lead us to the best hyperplane :
1. Confidence in making the correct prediction: Without getting into much detail (as the point of this post is to see why are support vector machines called so and not what they are), this intuition is formalized by the functional margin. The functional margin of a hyperplane given by 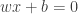
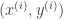

If 

If 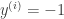
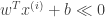
The above captures our first intuition into a single formal statement that we would like the functional margin to be large.
2. Margin: Another intuition about choosing the best hyperplane is to choose one in which the distance from the training points is the maximum. This is formalized by the geometric margin. Without getting into the details of the derivation, the geometric margin is given by:

Which is simply the functional margin normalized. So these intuitions leads to the maximum margin classifier which is a precursor to the SVM.
To sum up: To realize these intuitions and get the best hyperplane, the optimization problem is:
Choose 


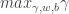
subject to the condition that 
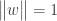
Working on the above optimization problem and trying to formulate it as a convex optimization problem leads to Support Vector Machines.
Also, the data I considered was linearly separable. We could easily extend the idea to non-separable data. For the general case, the dual of the support vector machines (for non-separable data) is given as:
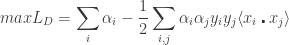
subject to:
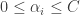

The solution is given by:
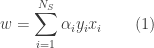
where 


[I have not made the above diagram by myself. I had taken it quite a while back and don’t remember from where. In case you do know, please do point out]
Now that a brief introduction is done, let’s come back to the main point.
In the above diagram we see that the thinner lines mark the distance from the classifier to the closest data points called the support vectors (darkened data points). The distance between the two thin lines is called the margin. The Support Vectors constrain the width of the margin. And since they are very less as compared to the total number of data points, they hand us many advantages but let us not get into that.
The question is, why are these points called Support Vectors at all? To understand this, consider a mechanical analogy. Consider that the data is in 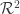



The solution 
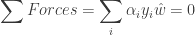
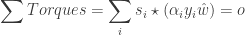
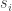

This mechanical analogy emphasizes two important points:
1. The most important data points are the support vectors as they have the maximum values of
2. Since the torque exerted by the support vectors comes out to be zero, we can say that these specific data points are “supporting” the hyperplane into “equilibrium”.
I think this explains how the term “Support Vectors” originates.
_____





Electronics engineering seems to have done no good to me. But shubhendu are you not from an electronics background as well? You have really done a nice job here with this post. Can understand a bit about the vector equations. But the prior part boggles my mind. Maybe it’s because of waking up early. Nice work!
Lot of similarities in the post to Prof. Ng’s lectures…
Absolutely, the discussion on the intuitions are based on his lectures.
However the last part isn’t from it.
In any case, I learnt all of my initial machine learning from Dr. Ng. :)
Yeah…Prof. Ng’s lectures are really amazing. I’m currently studying from them (am at Lecture 8!) and find them wonderfully lucid, even though I’m just a 2nd year undergraduate.
I intend to start working in the field of Artificial Intelligence as soon as I can, a subject I’m really interested in, although my major is in Electronics and Communications. Can you offer some advice on how to do independent (or guided) research in the field (for a beginner like myself)?
(I really like your blog, btw!)
Hi Divius Skimer!
First of all, thanks for the kind words!
Coming back, I think we share a common background. My undergraduate degree too was in Electronics and Telecomm. Engineering.
Prof. Ng’s lectures are a very good place to get started. And it seems you have picked up a good amount. I did something similar in second year. After that you could do some project in third year on Machine Learning (I did that, implementing a speech recognizer on a micro-controller and MATLAB both to make sure it took care of course requirements). That would really get you into it. As you do projects you will see more avenues and questions open up. Another good method is to do some summer research (going by your comment, you seem to be from India) at IITB / D (they offer fellowships) and get to work with a machine learning professor for some months. Maybe get a paper out in one of such works. You could also do a machine learning BTech project.
You could then get into a good univ. for masters in computer science (based on this work). Which could again have some ML research. You can then complete the transition by getting into a stronger CS PhD programme.
I think you are on the right path. Getting into such lectures in second year is definitely the right way of doing it. That would ensure you are prepared for more challenging projects next year onwards.
This is just one path.
Shubhendu
Hi,
Thanks a Lot for your helpful advice.
Doing an MS with specialization in ML is indeed currently my goal…your advice seems pretty sound to me; it’s more or less what I have planned out. The only problem in securing a good US university could be my college (IEM, Kolkata) which is kind of “never-heard-of-it”.
Right now, my to-do list is (I still have 3 weeks left in my summer vacations):
1. Finish CS 229. (I’m even doing the homework problem sets; sometimes peeking at the first step of the solutions.)
2. Try and apply SVMs to some application that uses ANNs mainly.
I might get more ideas as I progress through the lectures.
Thanks again!
Sorry for the delayed response. I was in transit. ;-)
Yes doing a MS would be helpful as it would ensure a PhD in a top ranked university contingent on if you are able to get out some good research in the first year of the same.
In the same vein, getting into a MS programme with funding after doing some good research in your under-grad is easier than doing the same for a PhD especially if the branch was different and the college less known.
BTW, my college was even more obscure. So much so that it was not known in the same city. The college ofcourse makes a difference. But don’t lose sleep over it. In the long run it doesn’t matter which college you did your undergrad studies in. What matters is what you did there.
I hope this re-assures you somewhat!
Shubhendu
Thank you, that is indeed somewhat reassuring.
I’m feeling really inspired and energized now!
I almost forgot.
Since you are doing CS 229. Supplement it with exercises from these set of lectures by Dr Ng.
Some of the exercises are pretty good first exercises.
These exercises look pretty good! Thanks for telling me!
Incidentally, I’m working on an implementation (in MATLAB) of Eigenfaces based Face Recognition based on your awesome tutorial, using the AT&T database.
Hi
Brilliant explanation to the term “Support Vectors”! Thank you!
[…] Image Credit […]
Great explaination!! I was really wondering for a long time why exactly are they called support vectors? Another question that was bothering me was why are naive bayes called naive? But I could find the answer of these. Many Thanks!!
You are most welcome and Thanks! :)
I do three things nowadays, approximately.
That’s; coding PHP, reading Stephen Hawking, and reading Shubhendu. :P
LOL! Jukka! :)
What a brilliant yet simple explanation of why SVMs are called SVMs at all. Thank you!
[…] here and in case the support vectors still sounds not too familiar I personally like to refer to this post that explains why SVM is called Support Vector […]
If number of support vector high means its good or bad? support vector is based on attributes or dataset?
Usually it is not a good thing, for it might indicate that you are overfitting. For the second question – it really depends, so in a way on both.
Great explanation. I have been wondering about this. :)
really a great explanation ..somthing outoff,,, well set bookish patterns..evrything i swel justified,,,
This was one of the finest articles that I have read on this topic. Thanks for the explanation!!
[…] https://onionesquereality.wordpress.com/2009/03/22/why-are-support-vectors-machines-called-so/ […]