Why?
Two Reasons:
1. Eigenfaces is probably one of the simplest face recognition methods and also rather old, then why worry about it at all? Because, while it is simple it works quite well. And it’s simplicity also makes it a good way to understand how face recognition/dimensionality reduction etc works.
2. I was thinking of writing a post based on face recognition in Bees next, so this should serve as a basis for the next post too. The idea of this post is to give a simple introduction to the topic with an emphasis on building intuition. For more rigorous treatments, look at the references.
_____
Introduction
Like almost everything associated with the Human body – The Brain, perceptive abilities, cognition and consciousness, face recognition in humans is a wonder. We are not yet even close to an understanding of how we manage to do it. What is known is that it is that the Temporal Lobe in the brain is partly responsible for this ability. Damage to the temporal lobe can result in the condition in which the concerned person can lose the ability to recognize faces. This specific condition where an otherwise normal person who suffered some damage to a specific region in the temporal lobe loses the ability to recognize faces is called prosopagnosia. It is a very interesting condition as the perception of faces remains normal (vision pathways and perception is fine) and the person can recognize people by their voice but not by faces. In one of my previous posts, which had links to a series of lectures by Dr Vilayanur Ramachandran, I did link to one lecture by him in which he talks in detail about this condition. All this aside, not much is known how the perceptual information for a face is coded in the brain too.

_____
A Motivating Parallel
Eigenfaces has a parallel to one of the most fundamental ideas in mathematics and signal processing – The Fourier Series. This parallel is also very helpful to build an intuition to what Eigenfaces (or PCA) sort of does and hence must be exploited. Hence we review the Fourier Series in a few sentences.
Fourier series are named so in the honor of Jean Baptiste Joseph Fourier (Generally Fourier is pronounced as “fore-yay”, however the correct French pronunciation is “foor-yay”) who made important contributions to their development. Representation of a signal in the form of a linear combination of complex sinusoids is called the Fourier Series. What this means is that you can’t just split a periodic signal into simple sines and cosines, but you can also approximately reconstruct that signal given you have information how the sines and cosines that make it up are stacked.
More Formally: Put in more formal terms, suppose 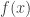
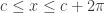
1. 
2.
3.
then
![f(x) = \displaystyle\frac{a_0}{2} + \displaystyle \sum_{n=1}^\infty [a_n cos(nx) + b_n sin(nx) ]\qquad(1)](https://s0.wp.com/latex.php?latex=f%28x%29+%3D+%5Cdisplaystyle%5Cfrac%7Ba_0%7D%7B2%7D+%2B+%5Cdisplaystyle+%5Csum_%7Bn%3D1%7D%5E%5Cinfty+%5Ba_n+cos%28nx%29+%2B+b_n+sin%28nx%29+%5D%5Cqquad%281%29&bg=ffffff&fg=333333&s=0&c=20201002)
The above representation of 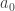


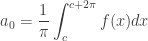
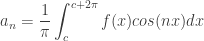
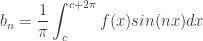
Note: It is common to define the above using

An example that illustrates 

A square wave (given in black) can be approximated to by using a series of sines and cosines (result of this summation shown in blue). Clearly in the limiting case, we could reconstruct the square wave exactly with simply sines and cosines.
_____
Though not exactly the same, the idea behind Eigenfaces is similar. The aim is to represent a face as a linear combination of a set of basis images (in the Fourier Series the bases were simply sines and cosines). That is :
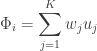
Where 
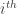
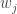
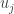
The big idea is that you want to find a set of images (called Eigenfaces, which are nothing but Eigenvectors of the training data) that if you weigh and add together should give you back a image that you are interested in (adding images together should give you back an image, Right?). The way you weight these basis images (i.e the weight vector) could be used as a sort of a code for that image-of-interest and could be used as features for recognition.
This can be represented aptly in a figure as:

Click to Enlarge
In the above figure, a face that was in the training database was reconstructed by taking a weighted summation of all the basis faces and then adding to them the mean face. Please note that in the figure the ghost like basis images (also called as Eigenfaces, we’ll see why they are called so) are not in order of their importance. They have just been picked randomly from a pool of 70 by me. These Eigenfaces were prepared using images from the MIT-CBCL database (also I have adjusted the brightness of the Eigenfaces to make them clearer after obtaining them, therefore the brightness of the reconstructed image looks different than those of the basis images).
_____
An Information Theory Approach:
First of all the idea of Eigenfaces considers face recognition as a 2-D recognition problem, this is based on the assumption that at the time of recognition, faces will be mostly upright and frontal. Because of this, detailed 3-D information about the face is not needed. This reduces complexity by a significant bit.
Before the method for face recognition using Eigenfaces was introduced, most of the face recognition literature dealt with local and intuitive features, such as distance between eyes, ears and similar other features. This wasn’t very effective. Eigenfaces inspired by a method used in an earlier paper was a significant departure from the idea of using only intuitive features. It uses an Information Theory appraoch wherein the most relevant face information is encoded in a group of faces that will best distinguish the faces. It transforms the face images in to a set of basis faces, which essentially are the principal components of the face images.
The Principal Components (or Eigenvectors) basically seek directions in which it is more efficient to represent the data. This is particularly useful for reducing the computational effort. To understand this, suppose we get 60 such directions, out of these about 40 might be insignificant and only 20 might represent the variation in data significantly, so for calculations it would work quite well to only use the 20 and leave out the rest. This is illustrated by this figure:

Click to Enlarge
Such an information theory approach will encode not only the local features but also the global features. Such features may or may not be intuitively understandable. When we find the principal components or the Eigenvectors of the image set, each Eigenvector has some contribution from EACH face used in the training set. So the Eigenvectors also have a face like appearance. These look ghost like and are ghost images or Eigenfaces. Every image in the training set can be represented as a weighted linear combination of these basis faces.
The number of Eigenfaces that we would obtain therefore would be equal to the number of images in the training set. Let us take this number to be 

_____
Assumptions:
1. There are
2. There are
3. All images are 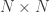

_____
Algorithm for Finding Eigenfaces:
1. Obtain 



2. Represent each image 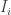


Note: Due to a recent WordPress 
 3. Find the average face vector
3. Find the average face vector 
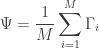
4. Subtract the mean face from each face vector 

5. Find the Covariance matrix 

![A=[\Phi_1, \Phi_2 \ldots \Phi_M]](https://s0.wp.com/latex.php?latex=A%3D%5B%5CPhi_1%2C+%5CPhi_2+%5Cldots+%5CPhi_M%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Note that the Covariance matrix has simply been made by putting one modified image vector obtained in one column each.
Also note that 

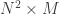
6. We now need to calculate the Eigenvectors 

7. Instead of the Matrix 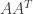
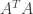
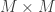


Now from some properties of matrices, it follows that: 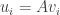

8. Find the best 


[6 Eigenfaces for the training set chosen from the MIT-CBCL database, these are not in any order]
9. Select the best
_____
Finding Weights:
The Eigenvectors found at the end of the previous section,
Now each face in the training set (minus the mean),

These weights can be calculated as :

Each normalized training image is represented in this basis as a vector.

 where i = 1,2… M. This means we have to calculate such a vector corresponding to every image in the training set and store them as templates.
where i = 1,2… M. This means we have to calculate such a vector corresponding to every image in the training set and store them as templates.
_____
Recognition Task:
Now consider we have found out the Eigenfaces for the training images , their associated weights after selecting a set of most relevant Eigenfaces and have stored these vectors corresponding to each training image.
If an unknown probe face 
1. We normalize the incoming probe 
2. We then project this normalized probe onto the Eigenspace (the collection of Eigenvectors/faces) and find out the weights.

3. The normalized probe 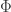


After the feature vector (weight vector) for the probe has been found out, we simply need to classify it. For the classification task we could simply use some distance measures or use some classifier like Support Vector Machines (something that I would cover in an upcoming post). In case we use distance measures, classification is done as:
Find 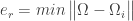
And if 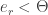
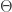
If however 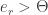
For distance measures the most commonly used measure is the Euclidean Distance. The other being the Mahalanobis Distance. The Mahalanobis distance generally gives superior performance. Let’s take a brief digression and look at these two simple distance measures and then return to the task of choosing a threshold.
_____
Distance Measures:
Euclidean Distance: The Euclidean Distance is probably the most widely used distance metric. It is a special case of a general class of norms and is given as:

The Mahalanobis Distance: The Mahalanobis Distance is a better distance measure when it comes to pattern recognition problems. It takes into account the covariance between the variables and hence removes the problems related to scale and correlation that are inherent with the Euclidean Distance. It is given as:

Where
_____
Deciding on the Threshold:
Why is the threshold,
Consider for simplicity we have ONLY 5 images in the training set. And a probe that is not in the training set comes up for the recognition task. The score for each of the 5 images will be found out with the incoming probe. And even if an image of the probe is not in the database, it will still say the probe is recognized as the training image with which its score is the lowest. Clearly this is an anomaly that we need to look at. It is for this purpose that we decide the threshold. The threshold

Click to Enlarge
Now to illustrate what I just said, consider a simpson image as a non-face image, this image will be scored with each of the training images. Let’s say 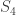
_____
More on the Face Space:
To conclude this post, here is a brief discussion on the face space.
 [Image Source – [1]]
[Image Source – [1]]
Consider a simplified representation of the face space as shown in the figure above. The images of a face, and in particular the faces in the training set should lie near the face space. Which in general describes images that are face like.
The projection distance 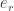
There are four possible combinations on where an input image can lie:
1. Near a face class and near the face space : This is the case when the probe is nothing but the facial image of a known individual (known = image of this person is already in the database).
2. Near face space but away from face class : This is the case when the probe image is of a person (i.e a facial image), but does not belong to anybody in the database i.e away from any face class.
3. Distant from face space and near face class : This happens when the probe image is not of a face however it still resembles a particular face class stored in the database.
4. Distant from both the face space and face class: When the probe is not a face image i.e is away from the face space and is nothing like any face class stored.
Out of the four, type 3 is responsible for most false positives. To avoid them, face detection is recommended to be a part of such a system.
_____
References and Important Papers
1.Face Recognition Using Eigenfaces, Matthew A. Turk and Alex P. Pentland, MIT Vision and Modeling Lab, CVPR ’91.
2. Eigenfaces Versus Fischerfaces : Recognition using Class Specific Linear Projection, Belhumeur, Hespanha, Kreigman, PAMI ’97.
3. Eigenfaces for Recognition, Matthew A. Turk and Alex P. Pentland, Journal of Cognitive Neuroscience ’91.
_____
Related Posts:
1. Face Recognition/Authentication using Support Vector Machines
2. Why are Support Vector Machines called so
_____
MATLAB Codes:
I suppose the MATLAB codes for the above are available on atleast 2-3 locations around the internet.
However it might be useful to put out some starter code. Note that the variables have the same names as those in the description above.You may use this mat file for testing. These are the labels for that mat file.
%This is the starter code for only the part for finding eigenfaces.load('features_faces.mat'); % load the file that has the images. %In this case load the .mat filed attached above. % use reshape command to see an image which is stored as a row in the above. % The code is only skeletal. % Find psi - mean image Psi_train = mean(features_faces')'; % Find Phi - modified representation of training images. % 548 is the total number of training images. for i = 1:548 Phi(:,i) = raw_features(:,i) - Psi_train; end % Create a matrix from all modified vector images A = Phi; % Find covariance matrix using trick above C = A'*A; [eig_mat, eig_vals] = eig(C); % Sort eigen vals to get order eig_vals_vect = diag(eig_vals); [sorted_eig_vals, eig_indices] = sort(eig_vals_vect,'descend'); sorted_eig_mat = zeros(548); for i=1:548 sorted_eig_mat(:,i) = eig_mat(:,eig_indices(i)); end % Find out Eigen faces Eig_faces = (A*sorted_eig_mat); size_Eig_faces=size(Eig_faces); % Display an eigenface using the reshape command. % Find out weights for all eigenfaces % Each column contains weight for corresponding image W_train = Eig_faces'*Phi; face_fts = W_train(1:250,:)'; % features using 250 eigenfaces._____





Wow! That was a really insightful post. I always love Machine Learning, but never have the time to dive into it. I will be interested in reading your next post regarding facial recognition. All the material that I have read on Machine Learning covered the algorithms, but never the actual implementation (I might not be looking hard enough). Also, as a side note, I would really be interested in reading a post on character recognition. Anyways, after all that, I have a question. Suppose that you have an image that contains faces and non-faces. How would you determine if there was a face in the image? You can’t take the entire image as your probe, because it would contain non-face and face features. You also have this problem for character recognition. How do you get around this problem?
Eldila,
I have not been blogging for a while. So I thought it was not a bad idea to post notes even if it was on a simple topic, I might do so for other talks (and the other part of this talk) more often from now on, especially in the first some months of this year.
Eigenfaces is actually a pretty simple tool, but works very well in a number of practical situations. The talk that I had to give actually involved a system on Gabor features along with Eigenfaces and support vector machines for the classification task. Also in that case the training data was pretty scarce.
I have never worked on a character recognition problem, but I have worked along on a information retrieval problem, and I can say that making a system with decent performance is not very difficult. I would sure try to post something on what features work well and why in character recognition tasks sometime for sure!
Your question is a very valid one. There are a host of preprocessing techniques used to come around that. Like face detection in an image (like the Turk Pentland paper to which I have provided a link to above has a simple method for face detection too actually) and then removal of background. Generally the preprocessing procedure involves locating the centers of eyes and then translating, rotating and scaling images to place them on specific pixels. Also for background removal the face may be masked. After masking the background and hair can be removed.
For an online authentication system that I worked on, the above was eliminated with the help of the GUI itself. We made the GUI such that the person had to adjust to “put in” his face and that eliminated most of the background. We did Eye detection using hough transforms to avoid unnecessary rotation of the face etc. So that way we could avoid the whole preprocessing task (other than the intensity adjustments ofcourse). But this worked for an authentication system as it allowed us to prepare specific models on where the eyes of the probe should be. I think for a online recognition task, at least some preprocessing other than intensity adjustments would have been required anyway.
hi..
i am doing projet on face recognition using eigen faces ..in java ..will u provide me the code for my project…
hey there’s link to matlab code in some of posts ..
It is of great help to me. My basic concept was really brushed up……..Thanks a lot for this blog……It is really helping us students at this beginning courses of B.E. If you don’t mind sir can you provide some code of it in Matlab as just started learning matlab it can help me a lot…….Thanks a lot for blogging it.
sir,
I am engineering student doing my last semester b.tech in electronics and communication.I am working on a project in face recognition(from videos)using eigen faces. Can u help me by providing
me with the matlabcode of face detection .
Here’s link to matlab code(http://www.filehosting.org/file/details/62302/eigenfce_pca.rar)
I must thank you M for your help to people here!
Hi M,
I’m looking for Matlab code that impliment this method .. I tried this link but I have not managed to download the code … please if you have this code, don’t hesitate to send me in this address hiba_rouahi@yahoo.fr
thank you in advance
Face detection? Check this out.
Wow amazing. You have started publishing research papers on your blog now! I like your pitch for eigenfaces. Any thoughts for automatically deciding the distance threshold? Even a supervised one?
Hi Shubhendu
I am currently working on a project with the intention to progress further into the development of androids. I would like to discuss a few issues with you.
Can you email me ur id?
btw – gr8 post on PCA, basic and to the point :)
Sure: Here – shubhendu_trivedi [AT] ieee [DOT] org
Good one Shubhendu!
Incidently, I saw a great application of face matching recently. BharatMatrimony.com has launched a service which will help you find a match who looks like celebrity of your choice :)
Interesting application.
Hi Paras,
My promised post taking up an example from your article is still pending. I had been keeping quite busy. It will be up tonight. He He.
And yes you are right. Very interesting application indeed.
And this is a very simple algorithm and frankly I was embarrassed to put it intially and happened to do it as I was not able to blog and I don’t like leaving the blog without any post for too long (and there is always a lot to write about), I was thinking of putting up notes to my talk on Active Appearance Models based methods. But yes Eigenfaces do give good results, especially when you use something like Support Vector Machines for classification instead of the simple distance measures.
– Shubhendu
And Paras,
Recently I attended a series of six talks given by Frédéric Bimbot, in his last talk which was a rather fun talk he spoke about some interesting applications (As an aside, Dr Bimbot has been of the best researchers I have met, very humble and very helpful irrespective of who you are or where you are from ).
As an example: They developed a very simple application in which you could find out with which celebrity or leader your voice matched the maximum. They deployed it at fairs and social events and it was a wonderful success.
– Shubhendu
This is a great post!
Hi this is great~
It is very informative to read…
I would like to have the code and understand more that you have mention above.
Plus i have some question to ask…
1) I am doing face recognition on LDA and some how is correlated to PCA. Let say i have found of the eigenfaces,
when i would like to do eulidean distance, what values should i input to the |x-y| there since i obtain a matrix. X and y here should be plots izzit ?
2)There is a graph on top of your blog classifying class A and class B. I would like to know how the graph is drawn in an efficient way.
And the x-axis and y-axis represent wHat?
Since computation of an image in matlab gives me matrix.
In a matrix form how can i draw a graph as such.
I have to thank you again for sharing what you know, those other section you are discussing really help me.
Would like to apologize due to the poor grammar.
Hope to hear from you soon :D
Hello sir,
The information which u provided in this blog is nice.
I am doing final year Btech in electronics and communication engineering. I am currently doing a project on “Face recogniton using Eigenfaces”. Can u please help me by providing the Matlab Source code for this project.
I would be greatful to u if u help me in this project.
hi
i am also an engineering student doing the same project….do u have the code in java..
Sorry my friend. I do not have the Java code, and would not have shared it for engineering projects in any case.
I only have coded it in MATLAB.
Thanks and Apologies.
– Shubhendu
@Daniel
1. The euclidean distance has to be found between the two weight vectors that you would obtain. One for the probe image and one for the template image.
2. Don’t take that graph very seriously. The “X and Y axis” I have just drawn for convenience. The figure aims to show two principal components. One is better at showing the relationship between the data, and the other is not so good. That would mean that the principal component that is better would represent the data better.
Thanks man i understand your points!!!
Currently i am doing face recognition using LDA
i have solve some of my doubt because of your great post here thanks again
can anyone please help me out eith a java code of eigenfaces algorithm????
Can you please send me sample codes for the above topics. Or probably the MathLab Codes.
thank you and good day!
Niel Lachica
hi shubhendu…..
i m an engg student .i need ur help regarding my project .i need face detection code in matlab.
Can you please send me codes for the project?
email id good4tilak@yahoo.com
Dear Tilak,
I would not provide any code if you have not read the instructions that i have given in the post properly. I have clearly mentioned that I MIGHT provide codes on an email request. I am not interested in doing your engineering projects by providing ready-made codes.
I don’t mean to be rude, but I have had enough of asking for codes unless there is a proper reason for the same.
– Shubhendu
Hi Shubhendu,
i am interested in learning the Mahalanobis distance. I have four mahalanobis distance calculated from two 4×1 vector.
How can i get normalized mahalanobis distance?
Do you have more information about mahalanobis distance?
Thanks alot.
Richie
nice post,
by the way, can you please explain about why we must use square matrix (or square image) as an input?
thx
Hi Chris,
Well, If you meant for images? The face images need not be square matrices.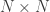 , I could easily consider images of dimension
, I could easily consider images of dimension 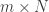 .
.
I have considered images of dimension
If you consider images of dimensions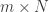 then the vector
then the vector  would be of dimension
would be of dimension 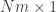 (I am using “m” instead of “M” to avoid confusion with the number of images).
(I am using “m” instead of “M” to avoid confusion with the number of images).
The matrix A would then be of dimension , however
, however 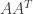 or the covariance matrix
or the covariance matrix  would always be a square matrix, irrespective of whether you choose square images or not.
would always be a square matrix, irrespective of whether you choose square images or not.
The matrix would have to be a square matrix as we are interested in finding the eigenvectors, and eigenvectors are defined only for square matrices. I hope I could clear your doubt.
would have to be a square matrix as we are interested in finding the eigenvectors, and eigenvectors are defined only for square matrices. I hope I could clear your doubt.
I really appreciate your presentation.
Please, I will be thankfull to get your Matlabcode to improve my understandings.
Regards,
Hello sir,
The information which u provided in this blog is nice.
I am doing final year Btech in electronics and communication engineering. I am currently doing a project on “Face recogniton using Eigenfaces”. Can u please help me by providing the Matlab Source code for this project.
I would be greatful to u if u help me in this project.
[…] trovato estremamente interessante ed esaustivo questo articolo che, nonostante presenti un esposizione formale in linguaggio matematico, è facilmente […]
hello sir,
I am an engineering student. I am doing project on
“face recognition using SVM” in Matlab . Your above post helped me a lot in doing the feature extraction using eigenfaces ,now i want to use the svm for classification using euclidean distance.
Can you please help me by providing steps for the classification .
I would be greatful to you.
thank you,
veena
Hello sir,
I am doing a project on Face recognition and reading old papers and journal for that.If you can provide me the matlab code for face recognition using eigenfaces it will really help me in understanding the algorithm .
Thank you
The explanation was very helpful, can you please send me the code thank you….
Balu
Dear Sir,
Really nice information ,Yet I didnt come across this much clear .I am very much interested on image recognition,thats way i have choosen project to do on Image recognition.
Could you provide the source code in Matlab.
Hello Shubhendu,
I have written code for eigenfaces. I am trying to use it for predicting whether a feature of interest is present in the test image.
However, I find that the distance measure (Euclidean) is not much different for positive and negative samples. So, I am unable to use a good threshold. Can you give me any pointers regarding where I might have to improve? I tried it on many kind of images including faces, but still the same. :(
I have normalised the eigenvectors of the final Covariance matrix AA^T.
Also, I am getting the final distance as order of 4. Is it right?
Do I have to normalise the weight pattern vector?
I am trying hard since many days without success.
So, if you could help, it would be great.
Thanks,
May.
Greetings May, :)
I understood you, I had a similar problem when I implemented it for the first time. The distance of course should not come like that, it should come very different for both positive and negative images.
Have you taken care of two things (these are what went wrong with my first implementation)?
1. I had not normalized what I have mentioned in Step 8.
2. You must be using 8-bit images right? Did you normalize by 255 after processing? Here’s a snippet of my code, this is for testing. Not for creating eigenfaces.
Apologize if I did not understand you correctly. Let me know if I could help further.
Much Respect,
– S
Here’s download link (http://www.filehosting.org/file/details/62302/eigenfce_pca.rar) to Eigenfaces code. Zip contains 4 Files M-file executing Eigenfaces, 3 MAT-files(matlab database files) containing ORL database(AT&T now). Unzip and run the code
Best
M
Hi Shubhendu, :)
Thanks for your help. I appreciate it.
You got my problem right.
I tried the normalization in point no. 2 of your reply and now it’s working fine, so the problem is solved. :)
Also, the distances are coming much smaller(max is a 2 digit number under 50).
(And to make it work still better I had to use fewer PCs than before. )
:)
However, I would like to know why do we need to normalise by 255 after resize and mean centering operations.
Gratitude and respect,
May.
Oh glad to know that I could be of some utility May! :)
Well it has been a while since I wrote the program and I seriously can not remember why I did it. :( I tried reading my old notes over the last two days also.
Well take that as an exercise! Try the second last line of the code without dividing by 255 and after doing so.
Add an extra step : Try to view that probe image after resizing for both cases and have a look at the pixel values.
Although I can hardly remember anything now, I think it has to do with two things. Firstly, conversion of datatype – uint8 to double, since many operations cannot be performed on uint8. Next, I’m guessing /255 is done to bring all the values between 0 and 1, since the range of uint8 is 0 to 255. Hope this helps. In case I remember. I will email you, I have your ID. (Bonjour! :)
Regards,
– Shubhendu.
Dear Shubhendu, Hi! I now perform project for face recognition and so I was very glad to read you nice tutorial, and I will try to use it! But I have one (but very important for me :) question. You (and a lot of other researches) suppose, that ALL images on the training set have same size and, moreover, they are square images. But is it correct? I agree, that by means of cropping we can manually extract faces from initial images and by means of re-sizing – to support same size (e.g., 19*19 pixels). But if initially the one face had size, for example, 20*30 and another had size 30*20, what we will get after re-sizing to 19*19 ? Proportions of our faces will be desroyted, isn’t it?
Same question about real recognition (after learning and threshold calculation) – on the testing set we have images with different proportions, isn’t it?
Thanks beforehand for your answer. Vika.
i actually try a few coding related to the eigenface. but it is hard for me to get results according to ghost face or eigenfaces , could anyone helping me give an idea or provide sample eigenfaces code and a short brief of how to use it . i have the database that i created about 50 images which is 5 diferent types of style for each person. and my measurement is on accuracy between 3 dominent features , eye, nose and face. i hope someone can help me to solve my problem . TQ
Dear Shubhendu, Hi! Sorry for my previously question. I myself have understood, that it is impossible to use different proportions for re-sized faces – we simply could not compare them!
But now I have next questions:
1. You have written on the Algorithm for Finding Eigenfaces: “1. Obtain training images , … “. Did you suppose, that all M images are positive, i.e. faces? (Classical SVM, for example, suppose, that Training set consists both from positive and negative images, isn’t it?)
2. I am understanding, that for SVM it is impossible to use direct coding (vector N*N) – amount of features will be too much! By why it is useful to implement Distance Classifiers based on Eigenfaces Approach? Why it isn’t enough to use direct coding? Reason is only computational problems for Mahalanobis Distance (for Euclidean Distance such problems are absent, isn’t it?), or some else?
Thanks beforehand for your answers. Vika.
@Vika,
I apologize for the much delayed reply. I was travelling and had limited access to the internet on my phone.
Please find my replies to your two comments inline:
1. For your previous question, I have already answered one part in this comment.
For the second part : Yes if you resize images which are originally of different dimensions to the same dimensions, your recognition accuracy would be hit.
But we are assuming that this is for a system where-in the camera remains the same for the recognition task.
2. When I say obtain training images. Let’s not confuse this with SVM. Here we are trying to obtain Eigenfaces and not trying to train a classifier in the real sense. So yes for a given class all the images would be positive.
For your second part of the question. I have written an article on face recognition using SVMs as well. I hope it would clear your doubt?
Respect,
– Shubhendu
Dear Shubhendu, thanks a lot for your answers. Regards, Vika.
hi
im working on a project named”face recognition using eigenface”,
i wonder if you would be kind enough to help me and
send me your matlab code via e-mail,
plz
Hi,
It was really very nice to read all what u have presented. Most of the sites fill their content with lots of equations and things that seems to be a bouncer. But your presentation was really very easy to understand and based on basics.
I thank you for sharing such a great work with us
thanks
joy
Dear sir,
These days, I’m following about Face recognition using Eigenfaces in MATLAB.
Can you please help me by sending MATLAB coding…..?
Thank you.
Here’s download link (http://www.filehosting.org/file/details/62302/eigenfce_pca.rar) to Eigenfaces code. Zip contains 4 Files M-file executing Eigenfaces, 3 MAT-files(matlab database files) containing ORL database(AT&T now). Unzip and run the code
Best
M
[…] 1. Face Recognition using Eigenfaces and Distance Classifiers – A Tutorial […]
Hi,
I’m working on Face detection using Eigenfaces (Reference Turk&Pentland 1991), In that paper they xplain constructing face map. I’m not getting how to code eqn 15 of that paper which is key of constructing face map..
@lasi
can u publish ur mail id i l mail u d code for recognition but it doesn’t include face detection(locating)..So u hav to manually crop face part n input the image for recognition..I’m workin on face detection at present..
Hi subendhu,
can u help me regarding face map for face detection..(Reference Turk and Pentland 1991)..
Best
M
@M
I have not implemented face detection as described in the Turk-Pentland paper. I used some other method for the same as the Pentland method was simplistic. Hence I don’t think I would be of much help.
Regards,
– S
I only used the recognition method above and the face representation using eigenfaces!
Didn’t do detection by this method.
Hello sir,
The information which u provided in this blog is realy nice.
I am doing final year B.E in instrumentation and control engineering. I am currently doing a project on “Face recogniton using Eigenfaces”. Can u please help me by providing the Matlab Source code for this project. actually am having already different source codes for the same but am unable to understand all those.
I would be greatful to u if u plz help me in this project.
Regards,
akriti
[…] MATLAB help.. MATLAB 7.9 – Demos Eigenface_Tutorial Face Recognition using Eigenfaces and Distance Classifiers: A Tutorial Onionesque Reality Eigenface Matlab […]
Hi Shubhendu Trivedi and all body here:
I am doing projet on face recognition using eigen faces ..my equsion is, how can I set proper threshold values from 0 to 1 as acheived the level of the system when it will be weak and when it to be so stronge system, which that based on the values of threshold setting. so I need to choose smallest and bigger value for threshold. could you help me to give me idea for this please. any body has idea please also forward it to me.
thanx
Essoo
Hello,
Thank you for your post, it’s very helpful.
I’m trying to implement the algorithm you provided and I’m getting some weird results.
When I compute the covariance matrix, I’m getting very large numbers. Then, when I compute eigenfaces, the result is not normalized. Are eigenfaces suppose to consist of large numbers (mean = 1.69946e+010)? if not – any ideas on what am I doing wrong?
Hi Shubhendu,
I am studying on face recognition for several weeks.. Getting very interesting! This is the best post I have found in internet. Thanks for that.
I am facing a problem. Like when it is matched and not matched the value of the distance is coming like 3.__e3(matched) and 1.__e4(not maytched).. Is it right? Can I make the variance more between matched and not matched?
Thanks..
Greetings Hassan,
You seem to have made a minor mistake. The error is in my opinion similar to the one made by “May” in above comments. Please check it up. I have also provided the code snippet in reply to his comment.
Respect.
S.
hello sir
great work being done over here
thnks to trivedi…..ur the edge
by the have small doubt
I have looked into the program u suugested “eigenfce_pca”
I couldnt understand how to have a look into the database in imspace(one of the file in the code) and the same with column and row
please do reply
thnk u
Hello Sir,
I m Subhadra. I m a final year student of E.T.E. I have been doing face detection & face recognition using eigen faces as my final year project. I have implemented your algorithm in this project & it has helped a lot. But I have a small request to u that if u can provide me the source codes of this project, I will be highly obliged to u.
Regards,
Subhadra
Sir
Am also planning to do the same project on embedded platform (TMS or Blackfin) ….. can u provide this same code as an fixed point code and embeddable code or u have any C source code……….. plz provide if any
thanks in advance ANUKRISHNAN
hello sir,
I am final semester M’sc Electronics student. I have written code for face recognition it working fine with known training set, but problem arises when image that is not in the training set takes up for the recognition task,as i would need to find threshold for random images. Can u elaborate more on calculating threshold of images.
Regards,
Dinesh Gaonkar
great work being done over here
my best wishes
Can u please inform me how to open(matlab database files) containing ORL database(AT&T now).
i want to have a look into the faces in the database
please do reply me
Sorry for delayed replay..I uploaded the code eigenface_pca. In mat file each image is converted column vector. I faced problem getting but not knowing how to execute when i started with face-rec. Thats why I kept “.mat file” in the package. To see image import .mat file into workspace resize n display..
thank u sir. you gave lot of information to me. sir iam doing project on “face recognitation using pca”but i didnt know sir how to find covariance matrix of using matlab .sir pls send me matlab code for to find covariance matrix sir
Naresh,
You don’t need a code to find the covariance matrix at all. Simply follow step 5 above.
S.
ok thank u
sir but I couldnt understand how to the image data base in .m
can be seen in the form of pictures
“To see image import .mat file into workspace resize n display..:is the reply u have given me earlier
can u please be a bit more clear
hi sir,
i am a final year software engineering student,i am doing a project:”Recognition of expression variant faces” they system should be able to recognise a person if he is smiley or angry…i want to know whether your post supports to this project…if not can u tell me a appropriate way to do this…
Thanks in advance,
Jaanu
hello sir,
your metrials is very good,
can u provide face recognition using
SVM
Hello Shubhendu,
Thanks for your excellent work. I’m actually from a much different field than yourself, mine being computational chemistry. I was hoping you could help me nonetheless. My question is pertaining to the Mahalanobis distance metric. The data sets which I deal with are large in dimensions, anywhere from 1000 to 5000 dimensions. I have used metrics such as the Euclidean, absolute value and dot product. I have been trying to get the Mahalanobis distance to work but to no avail. I have noticed in some place that the inverse of the covariance matrix cannot be found so different methods are used to get around this, such as SVD (single value decomposition).
What I am looking for is a metric which will take in two whole observations with say 1000 dimensions each and return a single value, by which they compare.
Could you suggest the best method for achieving this?
By mistake I posted an incomplete comment! Here is the complete comment.
Greetings Jimmy!
First of all thanks for the kudos.
I do use some metrics which originated in Computational Chemistry such as the Jaccard/Tanimoto index for similarity in MR image analysis.
What are you working on? I would be interested in knowing provided I can understand it. :)
Actually, I had faced a similar problem. In my original experiments, I had used about 2000 images. Which meant that without any dimensionality reduction each vector to be compared had 2000 elements. I had then used support vector machines (check the part on authentication and recognition for scoring). The end objective was using SVM in any case.
But I think for your application, it would not just be overkill but might not even be possible.
I also used Mahalanobis distance, but wasn’t sure if it was correctly done. Are you sure it can not be done?
Here is what I just tried on MATLAB.
Would this be correct? I think so, but I am not completely sure. And this would work for very high dimensional vectors as well.
I would also look for more metrics and email you / post here.
Respect,
S
Jimmy,
I would also be grateful if you could link me up with some literature which talks of using SVD etc for finding the inverse covariance.
I would want to solve this mystery for once and for all!
Though I am reasonably sure that the above is correct!
hello Shubhendu Trivedi:
actually i also facing a problem by using face recognition using PCA… i gt find all the eigenfaces from my train image but actually what is going to do to show eigenfaces in matlab (coding)…i using technique PCA izzit same with eigenfaces?
I just sent an email to your yahoo mail updating you on the Mahalanobis distance problem.
Regards,
jimmy.
Sir!
I am a student of computer science and need help on facial features extraction using MATLAB. I know it is possible through eigenfaces but how? I dont know.
Sir! i really need help on the topic. I will be really very thankful to you if you will provide some code for this.
Waiting for your reply………..
Regerds
hello, can u please provide the MATLAB program for the project of face recognition……….i need a working model for face recognition using eigen faces……
hii, Shubhendu Trivedi
I am doing a project based on face recognition using pca and i have compleated most of the project but I am struck at the point of finding threshold can u help me to find threshold
with regards
rohit varma
Assuming you want to set the threshold heuristically.
Make a table of all the distances for images within class (of the same person) and other class (of other people).
You will see that there is a big difference between the two in general. Choose the threshold between the two.
However in choosing so, you would have to make a tradeoff between false positives and false negatives depending on your application.
thank you for this hint :-) , can i sen you my code and help with it :-)
hi Shubhendu Trivedi
i’m dng a proj on face recognition so if u hav any codes wit u which can help me plz mail me d code. I need to recognize face depending on any algo.
with regards,
Rishab
Hi……this is an extremely useful tutorial wen implementing face recognition using eigenfaces…..i wanted to ask if u could provide a similar step-by-step procedure for ICA for face recognition….
regards
KN
Yes KN, that is in the pipeline, expect to see it in some time.
could u please give me an idea about how much time would it take? cz m workin on it as my final year project and the deadline for completion is the start of may….all the material available on net is either too complex or insufficient… so i m really looking forward to ur tutorial on it
Actually it is pending in drafts for over three odd months. It should have been up by January. I think I should take 15 days or so. This time of the year is the most hectic!
for eigenface, we implemented ur algorithm on matlab…followed exactly the steps u have written but threshold decision is really giving us problems…. could u give any advice about how to go about it? i think that our weights computation may be erroneous…. could u plz elaborate on how to do that part….
Greetings!
I suspect the problem you are having would be similar to what a commenter had earlier. I replied to his question on July 21, 2009. Check it up and tell me if it helps.
PS: I mentioned to him that I did not remember why I had divided by 255 in that code snippet. Actually, this is just so as to change your probe and training images to double.
Instead of using what I wrote there, since you are working on MATLAB, simply using im2double would suffice. Make sure all operations on images are done after a double conversion (from uint8).
hi….. i implemented both the steps u mentioned in that post…but still my distances are in the order of 10^4 …..could u plz tel me upto how much percentage of eigenfaces would give correct results? does the image reconstruction result in exactly the same image as in database? our reconstruction is not this way….i think there is some problem with weight calculation, could u plz elaborate on how to compute them?
Calculating the weights is a straightforward exercise with the formula I have mentioned (below point 9). Are you sure you have calculated the two vectors involved in the formula properly? And also, are you making sure that you are using the correct matrices for calculating the weights of the test image?
Face reconstruction should be exact if you reverse the steps exactly. Are you adding in the reconstruction step the mean image you have removed for example?
Hi Trivedi,
Your work was awesome and helped me to certain extent in my project. Do you have matlab code for this? Can you please send to my mail which can be helpful as small part of my project.
thanks a lot for ur help….we are finally successful in getting the reconstructed images as required….thanx again…. plz tell us about the minimum percentage of eigenfaces required for accurate recognition….
Glad to know the problem’s resolved.
There’s no definite answer to your question actually. I have noticed it varies as the data-set changes. You will have to choose the best PCs (Eigenfaces) and only use those for recognition. How to choose them can be done in the following ways.
1. You can start with taking all eigenfaces into consideration and then keep removing them in batches of 5 (or 2 or 10 depending on your data-set size and number of eigenfaces. And remove them backwards, i.e less significant ones removes first). And see what combination seems to give the best result. Once you seem to reach a point beyond which there is a reduction in accuracy, reduce the batch size so that you can zero in better to the optimal number (i.e suppose you have 70 eigenfaces, and you go backwards in batches of 5, suppose the accuracy at 55 was 78%, 50 76% and at 45 88%, and at 40 70%, then you know you can obtain better accuracy with a number between 40 and 50. You can then go one eigenface at a time, between these two limits ).
Side Note: Generally the first eigenface catches the maximum variance in the data and removing it helps making recognition robust to lighting conditions.
Try this trial and error method and also try keeping in the first eigenface and removing it.
Why to remove eigenfaces and the curse of dimensionality : It might seem to most of us that keeping all Eigenfaces would ensure best recognition but it might just be slow. It is not like that, there is an optimum number of features that would give the best accuracy. Any number less or greater than this would give worse results. This almost counter intuitive problem is called the curse of dimensionality. See a wonderful exposition of what I mean here
2. Another method to choose Eigenfaces is using the idea of class discriminability. That is — you keep the combination of Eigenfaces that show the maximum class discriminability. This is a pretty simple method and less tiresome than the above.
To see how this is done jump to page 7 of this pdf. and only check the part on “subspace selection”
Let me know if something isn’t clear enough. I will make a better attempt.
Hi,
Shubhendu , first off alll i must tell you your blog is great.
I just implemented Eigen Faces using Visual C++ and OpenCV.
There are 2 problems I am facing as of now:-
1.The Euclidean Distance is coming of the order of 5 for known faces eg values are:-
34224,19120 38610…
2.For unknown faces it is coming of order 6 eg,
201102,180119…
These values are coming after I have normalized the eigenfaces by dividing by255, before these where coming of the order of 8 and so on.
I have two questions:-
1.These values although are satisfiable but are still incorrect I guess, What else need to be normalized?
2.For an unknown face image the min distance is coming around 180119 but the max dist is too large like 588976.
Should’nt the distance of unkown face lie around a cluster from all the test images in the database>
Thanks in advance
hello ….every one..
I have a small problem on face recognition using PCA (eigen faces)
I have found the euclidean distances between a given image and all the rest of images in the database..
I want to know what is the formula or how to calculate the recognition rate of the recognition system
I want to use this recognition rate to be plotted across the (No. of eigen faces Vs recognition rate)and (eucledian distances Vs recognition rate)
Greetings!
This pdf should help you immensely. It is easily the best paper on this matter.
please help me in the above issue…for matlab programming
at this blog or to kkanth.v@gmail.com
Hello Sir,
Im Sucheta, A final year student of computer science. I am doing face recognition using eigen faces as my final year project. I have implemented your algorithm and it helped me a lot .
This is the best post I have found in internet.
Thanks…..
Hi, shubhendum
I had posted a problem earlier.
Now my euclidean distance are coming fine.
I was not taking the dot product. Now the problem is that the NON-FACE Class is coming near the face class.
The algorithm is not able to discrminate.
What might be the problem?
Also what is normalization of ear and eyes in training database?
Thank YYou
Hello sir,
I’m making a face recognition system using Fisherfaces.
I think it is very similar to Eigenfaces.
Currently, I use Euclidean distance to measure the distance.
I want to try using Mahalanobis distance but I don’t understand how to use it on my system.
Can you explain how to use it on face recognition system using Fisherfaces or Eigenfaces?
What the contents of x, y, and C?
I’m sorry for my bad English.
Regard,
Nata
hi shubhendum sir,
I am 3 year IT student of SLIIT in Sri Lanka.I am doing my final project “Face Detection and Recognition using Eigenface” in c# with openCV.I did my detection part very well using your examples , links and other your comments.
thanx for that sir..
But in my recognition part it doesn’t work properly.
I have method called FaceRecognition.Inside that i gave distance value 5000.
problem is, if i upload new face it cannot recognise properly…
but I have trained faces..those faces are recognize properly.If i give a low value than 5000…then new face recognition is KK.but then trained faces are not recognise properly..
please help me..
i have final presentations on next week.
can you provide code….to my email..
please sir..
I am in very bad situation..
plzzz….
how can i get grayscaled images for my face recognisation code and from where?
Hi
Im looking for code on the creation and implementation of Eigenimages that can help me get a better understanding of the use of the matlab code implementation. This will help me get an understanding and i can be able to use this to create eigenimages for finding lips in images.
thank you
anyhelp will be kindly appreciated
Hi,
I am start my fyp title of face recognition using eigenfaces + bpnn.
Is it possible that i browse a single image into my gui and then perform the eigenfaces extraction? Or it is a must that i build a folder contain of images to get those eigenfaces?
My idea is to browse a image and then let the system to classify it with eigenfaces + neural nets.
You can use your GUI to test an image. But to get eigenfaces you would have to create a library ofcourse. While creating your library too you would need that GUI.
Read my second comment on this post.
hi,
i am also doing the same thing.
could you help me with how to generate eigen faces and wat i/p should be given to the neural n/w
respected sir,
i am an M.E. computer science student in india.i am working on a project and doing research on face detection using eigenfaces.sir is it psoosible to mix facial feature extraction method and eigenface method to improve face detection rate.i mean can we extract features first using feature extraction method and thenuse eigenface method to detect faces.
respected sir,
I am student of MTech(CSE).My thesis is on Facial expression recognition with PCA and SVD and classifier is Euclidean based classifier.Kindly provide me code or help to acheive my results.
sir,
information posted here is very much useful.i am not able to understand how to choose threshold value in eigen face method for face recognition.Though, u have posted that we calculate score for each of training image and also for the unknown image.my question is how to choose thrshold value after getting scores for each of images.
Face recognition using SVM : Where I find the MAtlab code?
plz send the link in the followin adress
adharer_4lo@yahoo.com
hi,
m doing the same work cn u provide the link for the code
Man,
I can’t thank you enough for this great tutorial.. Thanks to you, i’ve understood the eigenface recognization process… Everytime i had a doubt about a notion, i visited your site.. I usually don’t post on website or blog, but you deserve this one: THanK You, you did a very good job ;)
Thanks!
You are kind! :)
I manage to get the eigenvectors and weights and show the eigenfaces in my desired directory. I am currently working on backpropagation neural network. The problems is how would I define the inputs and target of the NN in order to create NN?
Let say, I have a folder of training set consists of 20 images of 10 people where 2 images per person and another folder of testing set consists of 10 images of 10 different people. I would like to train the NN first and then test and classify the image that I browsed from my own GUI.
So, what should I put the in the inputs? The weight of each eigenfaces? or the eigenvectors? and output should be the weight/eigenvectors of the testing image?
Thanks in advanced.
Many Greetings!
Not eigenvectors! Weights are the signature of an image. Eigenvectors are of the ENTIRE training set.
Use weights to train!
S.
Sorry for my foolish question. For instance, I have 3 sets of weight calculated from 3 training images which are below:
2.6084 2.5761 2.3953
0.0263 -0.7147 0.3041
-0.4001 -0.0936 1.3525
-0.6091 0.4527 -0.1744
0.0386 -0.0789 0.2130
0.1610 -0.2925 0.1832
0.2960 -0.0210 0.0275
0.5177 -0.0298 0.0531
0.1056 0.6162 0.1593
0.3152 0.0297 -0.0430
So, I use this values to put into NN as my inputs and how about my output/target?
P/S:
From my understanding, weight can only be calculated in a sets of images(face library). But in my situation, I have to browse only 1 image from a test folder to test whether the image is being recognised. So, I have to calculate the weight in the test folder and save it as templates, too?
Okay.
See for the input you need to put in the weights as they are the signature of the image. Save weights for a class as templates from the training set.
For testing, send in ONE image and try to reconstruct it using eigenvectors that you had in the training set. You will get a set of associated weights. Now, use these weights to test against the template weights.
You can’t store templates of test images. Suppose I come in front of your system. :) Then what?
Sir,
How would I implement the reconstruction? Is there any algorithm?
What I’ve find out from the web is telling me to reconstruct by only using the top K eigenfaces as high eigenvalues contain more content.
Can I have your email so that I can discuss some problems with you?
Hi Ian,
Your problem is explained in the “Recognition Task:” section in the article above. I had tried to make this article complete! :)
Sure my email is in the “about page” of this blog. But expect somewhat delayed replies.
S.
Sorry for the previous post: I was just checking what could be wrong with your bmatrix environments. Simply put two backslashes instead of one to add new rows, and you should be fine. Feel free to erase both comments.
Hi,
Actually it was a temporary wordpress bug. I did write to them. And it is fine now. But I did not go back to correct it.
So I just added images from the cached page. :) The images are from the page when it was working fine.
Sir,
I have email u some of my results. I feel weird about my results where I get 20 weights from probe when i associated 1 test image with 20 training images and also the euclidean distances.
Please check your mail and correct me if I am wrong somewhere.
Sir,
My project is face recognition using neural netwok.
I extracting the feature with the help of pca.can u tell me
what should i give to nn for traing and how i will design the target vector and output. I m using ORL database in which there are 40 people and each people has 10 different pose, means i have 400 image.In which i m using 280(40*7) for training and 120(40*3) for testing.
[…] to Google and if you search long enough, you’ll probably find what you’re looking for: an entry-level tutorial explaining how Face Recognition works! For anyone like me who doesn’t know too much about Face/Image recognition, this is definitely […]
Greetings,
I have did some process to get the probe weight where I get something like:
1.0e+004 *
0.6115
0.2397
-0.9181
-1.1234
-0.1212
-0.3163
-0.0042
-0.0007
-0.6019
-0.5803
-1.0810
-1.0710
-0.7198
-0.7207
-0.2864
-0.2476
-0.1525
-0.1541
-0.2008
-0.1511
Is these results reasonable if I were to find the probe weight from 20training images?
Hi Ian,
I seem to have missed your comment. It has been a while.
But I hope the issue has been resolved!
Shubhendu
respected sir,
i want to know how to find the threshold value…..some of the paper are said that
theta=1/2(max(eulidean_distance)..
but it is not give the result accurate….
can u help me ……
sir,
i am doing my final year project in b.tech ece …….face recognition system is part of my project…….i have to compare the images stored in my database irrespective of lightning conditions,facial expressions.which method best suits my purpose????
i cant use pixel based system it gives lots of errors………
plz help me out……….in case eigen based system is helpful plz let me know from where i can get sound knowledge about it for coding in matlab……………
Thank you very much for your great tutorial.
Thanks Ali,
Much appreciated. :)
Hi Shubhendu Trivedi,
Firstly I would like to thank you for this tutorial is very interresting …
I am a student of master communication system and I am currently doing my project on the recognition and classification of facial expressions moyennat the ASM or the MAA … I need your help, I’m looking for Matlab code to impliment this method .. I tried this link http://www.filehosting.org/file/details/62302/eigenfce_pca.rar “but I have not managed to download the code … please do if you have this code does not hesitate to send me
thank you in advance
Hi Shubhendu Trivedi,
Firstly I would like to thank you for this tutorial is very interresting …
I am a student of master communication system and I am currently doing my project on the recognition and classification of facial expressions moyennat the ASM or the MAA … I need your help, I’m looking for Matlab code to impliment this method .. I tried this link http://www.filehosting.org/file/details/62302/eigenfce_pca.rar “but I have not managed to download the code … please do if you have this code does not hesitate to send me
thank you in advance
hiba_rouahi@yahoo.fr
nice post. .
i currently work on PCA Neural Network
i still confuse about the training image
to get result of pca of k people so i need k image??
or one people need k image??
hi,
i am doing project on face recognition using lda code, please mail me the code to my email id projects3c@gmail.com….. i have stuck there, i need your help
thank you.
This has been useful for our project and presentation.
Thank you for the neat explanation!
[…] Face Recognition using Eigenfaces and Distance Classifiers: A Tutorial « Onionesque Reality (tags: eigenface face-recognition) […]
please i need a help for my final project face-recognition using AAM whith matlab and i don’t find in internet the code in matlab
i have implemented face recognition using eigenfaces in matlab.now using all the projections and distances as a weak classifier i want to perform boosting using adaboost algorithm to make a strong classifier.but i am unable to understand how can i make a weak classifier.please guide me.
hello sir
i am doing master in taiwan , , but i read ur post ,which was very helpful to me , thank u sir
Thanks! :)
Hey Shubhendu Trivedi,
Thanks for the post. I found it very helpful at understanding the end steps in the PCA algorithm involving distance metrics and how to classify a probe image.
Again thank you for the post
Thanks for the kind words! :)
hi,
i am doing project on face recognition using pca code, please mail me the code to my email id kamelcom@live.com….., i need your help
thank you.
hi,
i am doing project on face recognition using DCT_PCA code, i have pb in DCT coeficients after application the PCA, the coeficients DCT are change as gaussien or as exponential way???????????????????????
please mail me the code to my email id kamelcom@live.com….., i need your help
thank you.
hi,
i am doing project on face recognition using DCT_PCA code, i have pb in DCT coeficients after application the PCA, the coeficients DCT are change as gaussien or as exponential way???????????????????????
please mail me the code to my email id baasma2009@live.fr….., i need your help
thank you.
j’ai une question:
comme d’abitude PCA utiliser pour la verification du visage
est ce que la PCA peut etre fait pour la verification ??????
et comment????????????????????????????????
Hi all… i am doing mater degree project on face occlusion detection and restoration.can you help me to get matlab code for dual tree discrete wavelet transform
Hello, Excellent tutorial of the eigenface approach to recognition! I must admit however, that I got lost at steps 5, 6, and 7 of the algorithm. I am trying to work an example of a simple 2×2 ‘image’ by hand to fully understand the process. Could you help with an example of determining the covariance matrix “C” showing the work with a small sample of 3 images that are 2×2 images?
The equations in steps 5-7 have confounded me for weeks now, and I haven’t even gotten to step 8. Thanks a bunch if you can help me!
[…] https://onionesquereality.wordpress.com/2009/02/11/face-recognition-using-eigenfaces-and-distance-cla… Share this:EmailPrintFacebook This entry was posted in 無關線代 and tagged eigenface, 視覺藝術, TED 演講, 主成份分析. Bookmark the permalink. ← 從實數域到複數域 每週問題 July 27, 2009 → […]
What is Covariance matrix for?
What is the purpose for finding Covariance matrix?
It is a concise representation of all the (second order) variations between all the images taken pairwise. Note that each element in the covariance matrix is an encoding of the variation between two different faces (except the diagonal). Thus, the matrix as a whole represents variations between all the images in a sense.
What do you mean by second order variations and how about the other orders?
I also not quite understand about the “except the diagonal” part.
Can you also show some diagrams so that it can help me to understand better.
Thank you.
John,
Let’s say you have a bunch of images and you want to construct a concise matrix that takes into account variations of each image with ALL others and with itself. One could see that such a matrix would be much easier to deal with than all the images at the same time. One way of doing this is the covariance matrix (a similar one is called the Graph laplacian)
Now let’s represent these images as column (or row) vectors. Covariance is a single number that gives a measure of how are two vectors (random variables) changing with respect to each other. Covariance of a vector with itself is the variance. These give a good idea of how the vectors are changing.
Now in our case we want to construct a concise representation of a set of images. Let’s say we have 100 images. That means we have 100 vectors.
Now we go about constructing the matrix like this – the element (1,1) of the matrix would be the covariance of image 1 with itself. (1,2) would be of image 1 with image 2 and so on. So we would always get a square matrix. I said diagonals because that would be the covariance of an image with itself (i,i).
This is second order. Covariance can only model second order moments. For higher order changes you would have to use something like ICA.
I hope this helped?
– Shubhendu
Hi Shubhendu Trivedi, thanks for the post. I followed each step. Now when I normalize the eigen vectors of AtA, and plot it, those are not eigen faces rather when I plot them without normalizing , i get eigen faces. Am I wrong somewhere?
Thanks,
Karthik
Karthik,
As long as you are getting Eigenfaces, I think you are fine!
hi.. we are going to do final year project in face recognition using eigenfaces.. we need detailed explanation of euclidean distance and threshold value…
Can you elaborate what is weights?
Thanks for this Explain and i so happy for applied this algorithm in my security Project and has been successfully complete for all step(s)…
notice for another algorithm to applied … (^_^)
Sincerely,
i use the eigenfaces and wrote the code on matlab …. when i try to test the program with a picture from the data base it works fine , but when i use the camera to capture a picture and try to recognize the picture taken it’s not working well and it recognize a wrong face img ….. so what do you advice me to do :( ??
Very nice article! I am quite interested in this stuff and I have already built my own version in Matlab. Now I was wondering if you have ever experienced the following problem too. When I submit non-face pictures with skin-color to the algorithm, I am not able to distinguish these from real faces. So despite the fact there are no eyes or mouth in the non-face picture, the skin color is enough to label it as a face. Have you ever heard of this problem? Do you think some sort of preprocessing step is required to solve this? Thanks!
Hi, I am not sure, but if you have already tried this – This might help:
Also build a “garbage” class of images having no faces but the same colour, this would ensure that during training this particular anomaly is taken care of. That might be helpful as you might get a finer threshold that takes care of this.
the file eigenfce_pca.rar can be uploaded from here:
http://www.mediafire.com/?kk5h9ms6sk1r6fb
awsome blog! Infinitely helpful. :D
Hi,
Im a Final Year university student doing a project on particle recognition based eigenfaces + PCA.
Im done most of the parts. the problem im having now is that example, if i have 100 images in my database, but i would like to choose best 40. How do i achieve that?
i know the steps like firstly i have to find the correlation coefficient of the 100 images.
Once i found the Corr coef, i rank them according to lowest to highest.
therefore i choose the lowest 40 .
but i no clue how to find the corr coef. Do u have any clue?
please do reply me @ “dianella.ensifolia@hotmail.com”.
ur help will be much appreciated!
Thank you! :))
Sorry. I just saw this. :( I had switched the notifications from the blog off for some reason. Is it too late for an input now?
hey ur illustration is very good !
keep it up
I used to be suggested this blog through my cousin. I’m now not certain whether this post is written through him as no one else understand such exact approximately my problem. You are incredible! Thanks!
Thanks for the kind words! :)
Hi
tried this face recognition using eigen faces …
working fine :-)
have a doubt
1. any thumb rule to select eigen vectors where u have mentioned they are chosen by heuristics
i even neglected the projection along the three maximum eigen vectors and still it seems working fine …i did it because i foud the dynamic range of the data too high as i was implementing it on a DSP processor ….
i cant visualise the connection between pattern reconstruction and recognition
because reconstructing the pattern would require me to use the projection along maximum eigen values
i used the yale face database B type
btw thanks a lot for ur tutorial … am from IIIT Madras and I find ur blog quite interesting :)
Thanks for the kind words. :-) I am happy that this post was useful. Although I keep thinking that I need to clean it up given it was written almost 4 years ago now!
For your question: A principled way would simply be to run a grid search (a coarse one at first and then finer) on the training set to find the best number of eigenvectors. Since there are not too many eigenvectors to deal with, it typically runs very fast. It would be hard to have accurate rules of thumb on how many eigenvectors to choose.
In the post, it’s mentioned that ||u_i|| = 1 after we get it by u_i = A v_i. Not sure whether it’s true.
Hi Ying, took me some time to recall. This was written a long time ago. :)
The point there is to say that once you’ve obtained the eigenvectors (which will be the Eigenfaces basically), it useful to normalize them to 1 for the later steps. Perhaps there was some ambiguity in that line — I didn’t mean to say that the output there would be normalized to 1 automatically, if that is what it came across as.
Thanks,
Shubhendu.
I see. Yes, I thought you might mean that you need to normalize u_i, but it is not very clear from the post. I really like your post though, especially about how you relate it to Fourier series. Very nice for building intuitions.
Thank you. I was just running through the post and realized that it needs to be severely edited! That aside, I think probably a discussion about change of basis would be both relevant and useful. I should probably do that sometime!
[…] on the mathematical aspects but if you are interested on those, you can look at the excellent post Face Recognition using Eigenfaces and Distance Classifiers: A Tutorial from the Onionesque Reality […]
[…] I am trying to make hand gesture recognition using (PCA) by python. I am following the steps in this tutorial: https://onionesquereality.wordpress.com/2009/02/11/face-recognition-using-eigenfaces-and-distance-cla… […]
hi i have developed a matlab code using eigen face for face recognition using webcam
but i want to use it as a laptop login instead of writing password
so how can i implement it
plz help me
Hi, have you also written a paper on eigenfaces? I would like to reference few of your ideas, would be nice if i could point to a research paper instead of a blog.
Best regards!
Hi Janis,
Thanks! Unfortunately I don’t have a paper on Eigenfaces. But thanks for considering to cite this article!
Shubhendu.
hi, thanks for your tutorial.
about link for the code…its not found.
could you email me to pelaksanatugas@gmail.com
and i have little ask…can we convert, in some way, the distance to percentage?
thanks…
Hello,
Thanks for the nice code and explanation. Please, I have done this perfect method of face recognition (PCA+Euclidean Distance) , I just want to calculate the accuracy of how PCA does the recognition using Eu dis?? So, please help me :)
Kumar
[…] on the mathematical aspects but if you are interested on those, you can look at the excellent post Face Recognition using Eigenfaces and Distance Classifiers: A Tutorial from the Onionesque Reality […]
heloo am engineering student .. am doing my final year poject .. can u provide me the recognition code in c# .. it would be really helpful
Thanks so much for the article.Much thanks again. Great. daeabedecgae
Hello sir,
I have understood how PCA works. I had one doubt though.
As you explained, that once we have found the eigen vectors and the weight vector for each image, we have to store them and for recognition purpose we have to normalise the new probe and project it onto the same eigen space. What I am doing is calculating the eigenvectors and weight vectors for each image and stroing it in a .txt file and while recognition I am loading the file again and trying to project it on the same space.
But the size of the new image or the probe is different than that of the training images and it is showing the error of size not being same!!
Please can you help me with this issue. Also, please can you update the post and state the size of the eigenvectors and the weight vectors. I think I am still not clear on calculating the weight vector.
Thank You!!!
[…] https://onionesquereality.wordpress.com/2009/02/11/face-recognition-using-eigenfaces-and-distance-cl… […]
Respected sir.
I have implemented some of the codes for face recognition.but I m not getting accuracy with the results. The known face from d database shows face recognition failure n sometimes vice versa.. Plzzz do help me:- dhvani.patel70@yahoo.com
Reblogged this on The Prodigal Prodigy. and commented:
IP using PCA
hi sir, i run this code of yours in matlab, but then it said undefined variable raw_features..can you help me?
Heyy! I have one question. What do you mean by score between the input image and database image under calculation of threshold
This post provides an amazing insight
Thanks